Google startet PaliGemma: Sein erstes offenes multimodales Vision-Language-Modell zur Verbesserung der KI-Fähigkeiten
Most people like
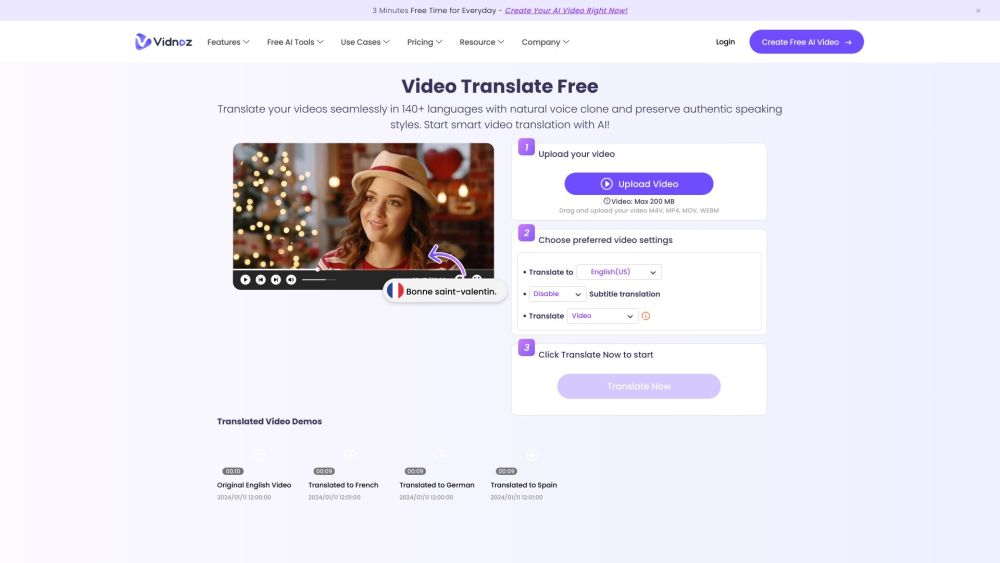
Übersetzen Sie Videos in über 140 Sprachen in nur 3 einfachen Schritten!
Entfalten Sie das globale Potenzial Ihrer Inhalte mit unserem leicht verständlichen Prozess zur Übersetzung von Videos in mehr als 140 Sprachen. Ob Sie ein breiteres Publikum erreichen oder das Engagement Ihrer Zuschauer steigern möchten, unser optimierter Ansatz sorgt dafür, dass Ihre Botschaften weltweit ankommen. Verabschieden Sie sich von Sprachbarrieren und begrüßen Sie ein stärker verbundenes, mehrsprachiges Publikum!

Akkadu bietet KI-generierte Untertitel in Echtzeit und verbessert das Verständnis von Videos und Live-Events in mehreren Sprachen. Diese innovative Technologie ermöglicht es dem Publikum, Inhalte problemlos zu verfolgen und sorgt für eine nahtlose mehrsprachige Zugänglichkeit.

Entdecken Sie die Möglichkeiten der Automatisierung und revolutionieren Sie Ihr Leben. Erfahren Sie, wie die Nutzung von Technologie Ihre Aufgaben vereinfachen, die Produktivität steigern und in sowohl persönlichen als auch beruflichen Bereichen bedeutende Veränderungen herbeiführen kann.

Präsentation unserer innovativen, KI-gestützten Personal-Training-App, die darauf ausgelegt ist, Ihr Fitnesserlebnis zu Hause oder im Fitnessstudio zu optimieren. Dieses hochmoderne Tool passt die Trainingspläne an Ihre individuellen Ziele an und stellt sicher, dass Sie aus jeder Einheit das Beste herausholen. Egal, ob Sie Anfänger oder erfahrener Sportler sind, unsere App passt sich Ihren Bedürfnissen an und bietet maßgeschneiderte Routinen, die Ergebnisse maximieren und Sie motivieren, auf Kurs zu bleiben. Machen Sie sich bereit für eine transformative Fitnessreise, die Ihnen direkt zur Verfügung steht!
Find AI tools in YBX
Related Articles
Refresh Articles