NVIDIA Presenta un Nuevo Modelo de IA de 8B: Alta Precisión y Eficiencia, Compatible con Estaciones de Trabajo RTX
Most people like
Desbloquea el Éxito en Ecommerce con Creación de Contenido impulsada por IA
En el competitivo mercado en línea actual, aprovechar la generación de contenido mediante IA puede mejorar significativamente tu estrategia de ecommerce. Al automatizar y optimizar la creación de contenido, puedes interactuar con los clientes de manera más efectiva, mejorar los rankings en buscadores y, en última instancia, aumentar las ventas. Descubre cómo aprovechar el poder de la inteligencia artificial puede elevar tu negocio de ecommerce a nuevas alturas.
Podsqueeze utiliza tecnología avanzada de IA para crear contenido de podcast atractivo, incluyendo notas de episodio detalladas, marcas de tiempo precisas y boletines informativos. Transforma tu experiencia de podcasting y mejora la interacción con la audiencia con nuestras soluciones innovadoras.
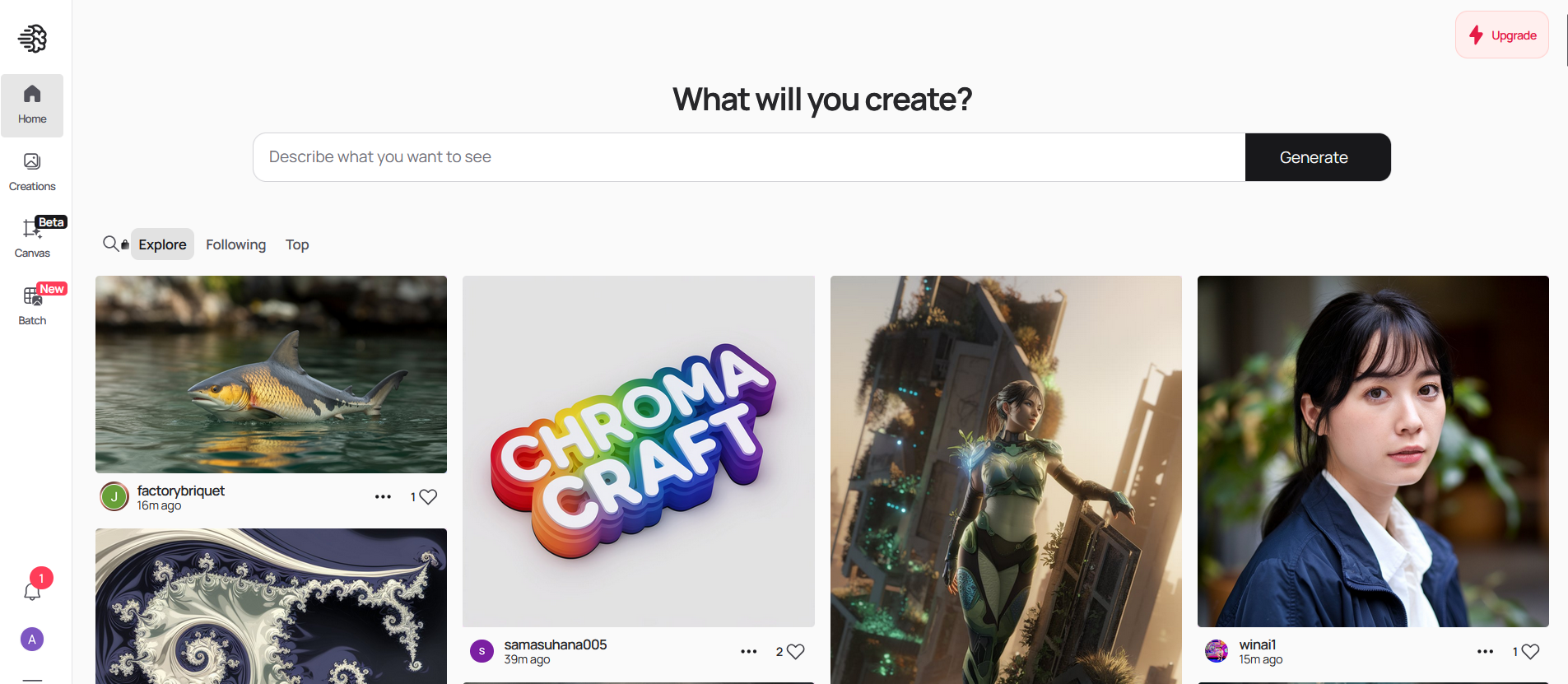
Ideogram es una herramienta de AI de uso gratuito que genera imágenes realistas, carteles, logotipos y mucho más.
Find AI tools in YBX
Related Articles
Refresh Articles