Amazon enquête sur Perplexity AI suite à des allégations de collecte non autorisée de données sur des sites web.
Most people like
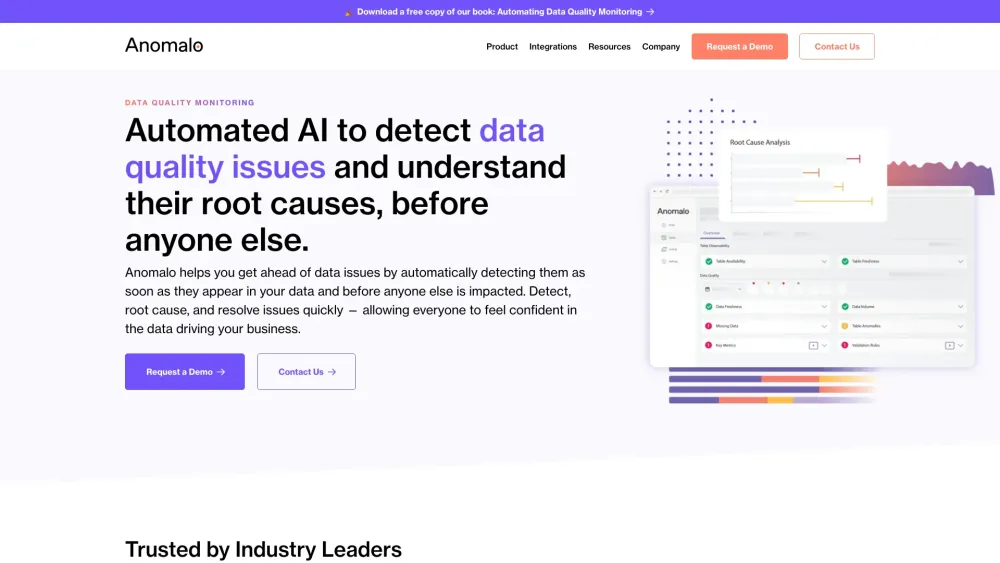
Révolutionnez votre gestion des données avec notre solution d'IA automatisée conçue pour identifier rapidement et résoudre les problèmes de qualité des données.
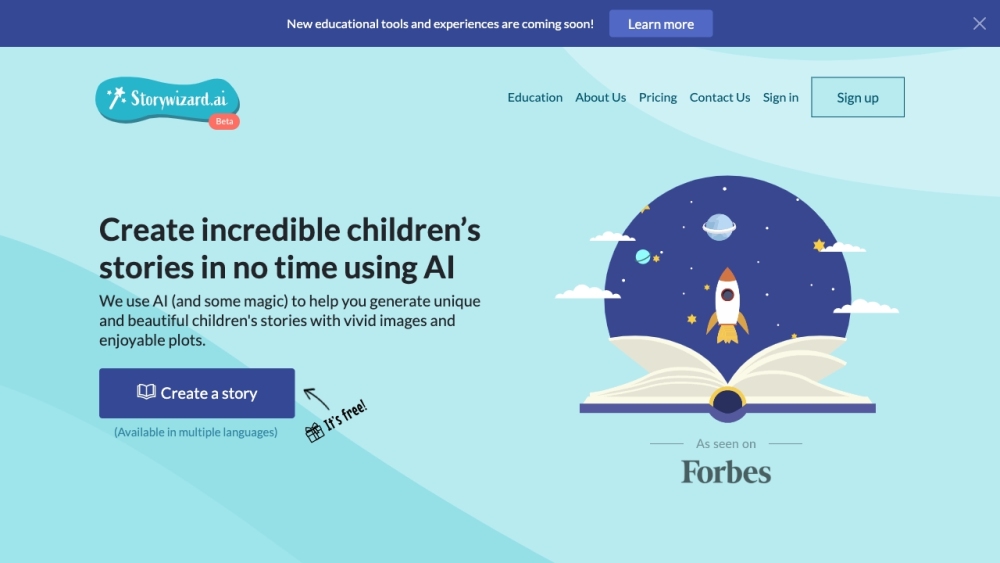
Découvrez une plateforme de pointe qui utilise l'intelligence artificielle pour offrir des expériences éducatives sur mesure, spécialement conçues pour les enfants.
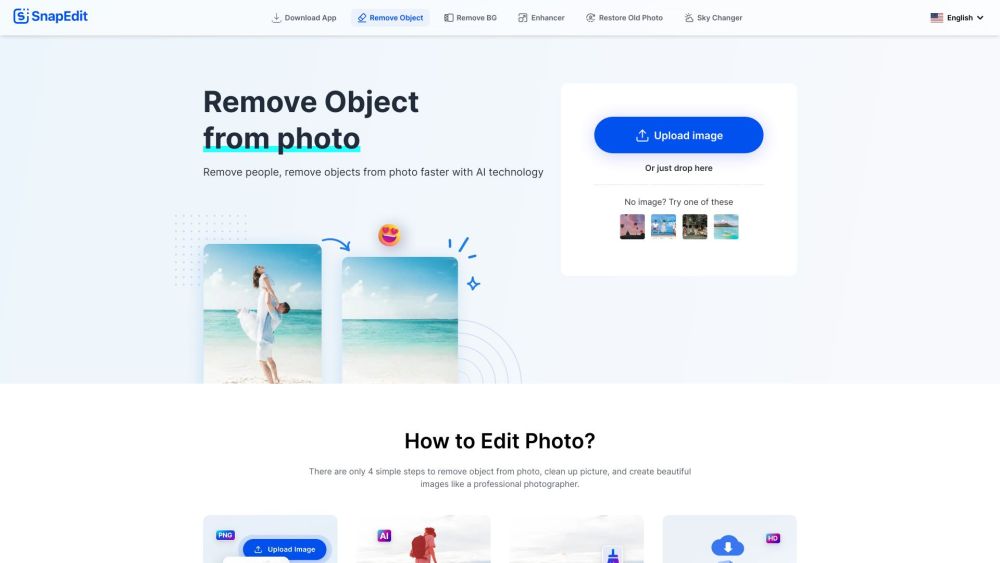
Découvrez SnapEdit.App, un outil de retouche photo en ligne gratuit qui exploite la puissance de l'IA pour éliminer sans effort les objets et les personnes indésirables de vos images, tout en améliorant leur qualité globale. Vivez l'avenir de la retouche photo grâce aux fonctionnalités intuitives de SnapEdit, conçues pour sublimer votre photographie.
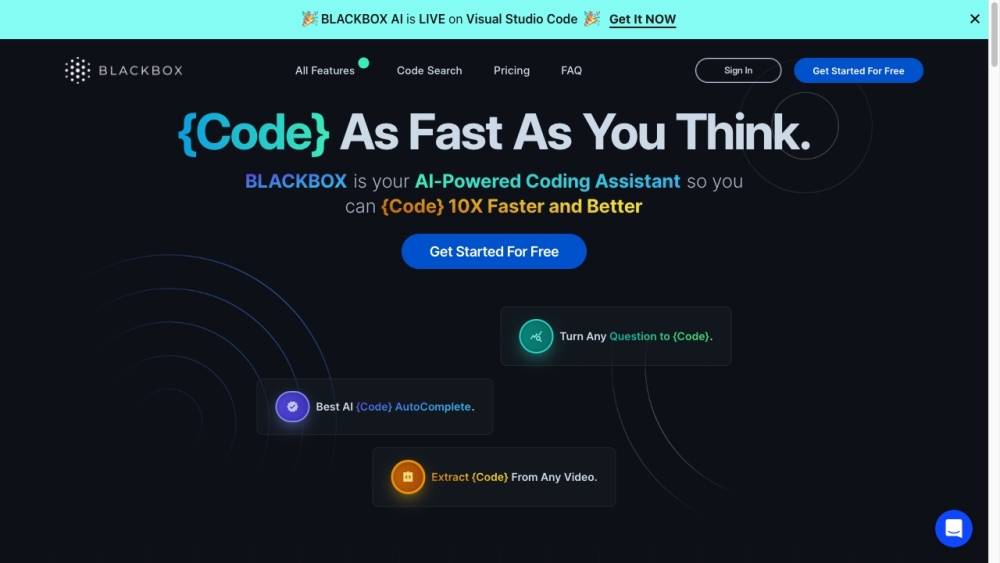
Présentation de Blackbox : un assistant de codage alimenté par une IA, conçu pour améliorer la productivité des développeurs et optimiser leur flux de travail. Grâce à ses fonctionnalités innovantes, Blackbox permet aux programmeurs de coder de manière plus efficace et efficiente.
Find AI tools in YBX
Related Articles
Refresh Articles