Débloquer le modèle d'IA 'Remarkable' qui propulse les capacités multimodales améliorées de ChatGPT
Most people like

Générez rapidement du contenu de haute qualité en quelques minutes avec ContentGenius, idéal pour les réseaux sociaux, les communications professionnelles ou le travail académique.

Débloquer le potentiel des solutions de traduction IA pour vos besoins commerciaux variés
Dans le monde interconnecté d'aujourd'hui, une communication efficace est essentielle au succès des entreprises. Les solutions de traduction IA transforment la manière dont les entreprises fonctionnent en déconstruisant les barrières linguistiques et en permettant des interactions fluides entre les cultures. Que vous vous développiez sur de nouveaux marchés, collaboriez avec des partenaires internationaux ou apportiez un soutien à une clientèle mondiale, tirer parti des technologies de traduction avancées peut améliorer vos opérations et stimuler votre croissance. Découvrez comment ces solutions innovantes peuvent répondre à vos besoins commerciaux uniques et rehausser votre stratégie de communication.

Dans le monde visuel d'aujourd'hui, des visuels de haute qualité sont essentiels pour capter l'attention du public. Heureusement, les avancées en intelligence artificielle (IA) révolutionnent l'amélioration de la qualité des vidéos et des photos. De la correction automatique des couleurs à la réduction du bruit, ces outils innovants offrent aux professionnels créatifs et aux passionnés la possibilité de transformer leur contenu visuel sans effort. Découvrez comment l'intégration de la technologie IA peut sublimer vos images et créer des résultats époustouflants qui se démarquent dans le paysage concurrentiel actuel.
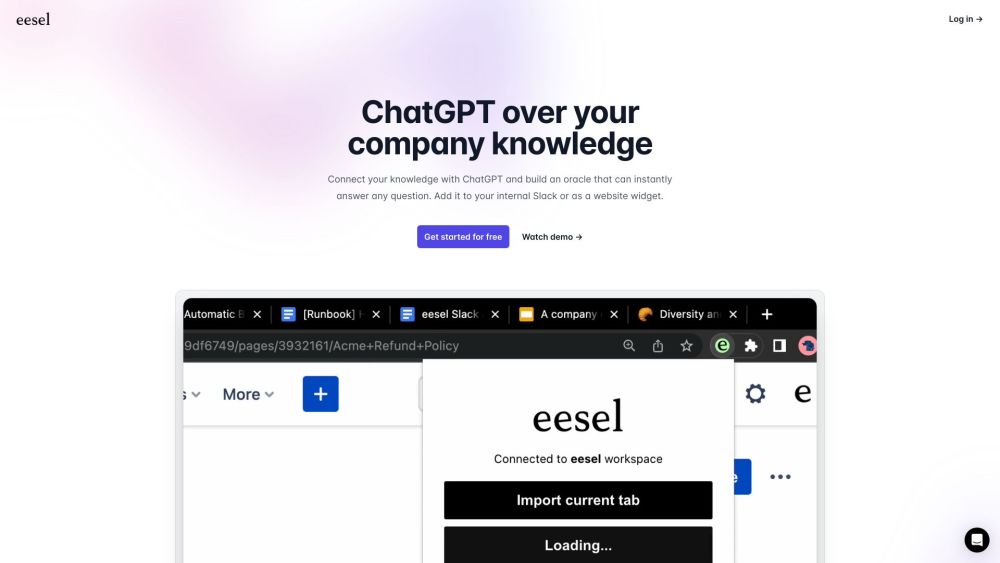
eesel.ai est une plateforme innovante qui intègre harmonieusement le savoir avec ChatGPT, créant un puissant oracle de questions-réponses. Grâce à eesel.ai, les utilisateurs peuvent facilement accéder à des informations précises et des insights, améliorant ainsi leur expérience d'apprentissage et de prise de décision.
Find AI tools in YBX
Related Articles
Refresh Articles