H2O AI Présente Danube : Un LLM Ultra-Compact Optimisé pour les Applications Mobiles
Most people like
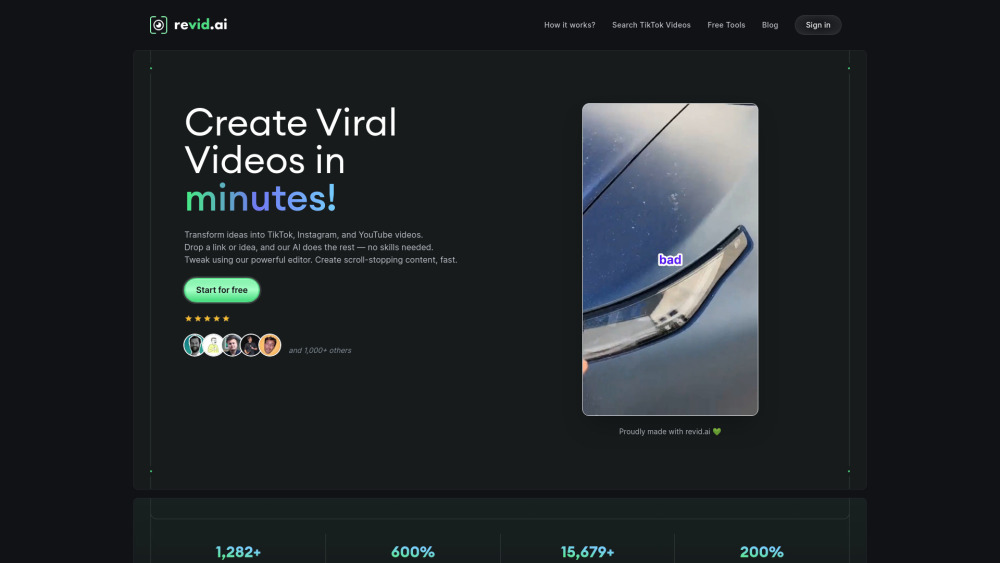
Déverrouillez la puissance d'un outil alimenté par l'IA, conçu pour créer des vidéos courtes virales captivantes sans effort. Cette solution innovante exploite une intelligence artificielle avancée pour simplifier la production vidéo, garantissant que votre contenu attire non seulement l'attention, mais résonne également auprès des spectateurs. Que vous soyez créateur de contenu, marketeur ou entrepreneur, cet outil rend la création de vidéos engageantes et partageables plus simple que jamais. Adoptez l'avenir du marketing vidéo et regardez votre audience croître !
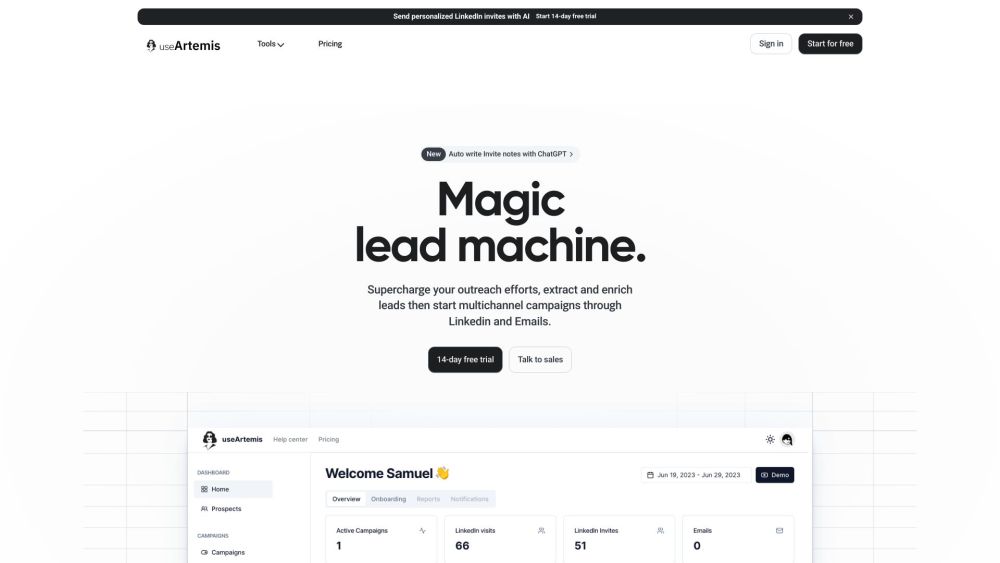
Découvrez comment trouver facilement des prospects de haute qualité, enrichir leurs profils avec des adresses e-mail et lancer des campagnes de marketing multicanal efficaces. Transformez votre stratégie de prospection et maximisez votre potentiel de conversion dès aujourd'hui !
Découvrez notre plateforme d'IA avancée, conçue spécialement pour le sourcing, la vérification et le paiement des employés de manière fluide. Élevez votre processus de recrutement grâce à une technologie de pointe qui optimise le recrutement, vous garantissant de trouver rapidement et facilement le bon talent. Avec nos solutions innovantes, la gestion des paiements des employés n'a jamais été aussi simple, permettant à votre entreprise de prospérer dans un paysage concurrentiel.

Créez des logos professionnels époustouflants sans effort avec Logomaster.ai. Notre plateforme intuitive, dotée de suggestions avancées d'IA, vous permet de concevoir des logos accrocheurs en seulement 5 minutes.
Find AI tools in YBX
Related Articles
Refresh Articles