Kneron Renforce l'IA en Bord avec des Améliorations de l'Unité de Traitement Neural et de Nouvelles Fonctionnalités pour le Serveur Edge GPT.
Most people like

Présentation de votre assistant alimenté par l'IA pour une gestion quotidienne des tâches sans effort
Dans un monde où le temps est précieux, disposer d'un assistant alimenté par l'IA peut transformer votre gestion quotidienne des tâches. Découvrez le mélange parfait d'efficacité et de commodité, vous permettant d'optimiser vos routines, d'améliorer votre productivité et de vous concentrer sur ce qui compte vraiment. Dites adieu à l'accumulation et bonjour à une vie quotidienne organisée et sans stress !
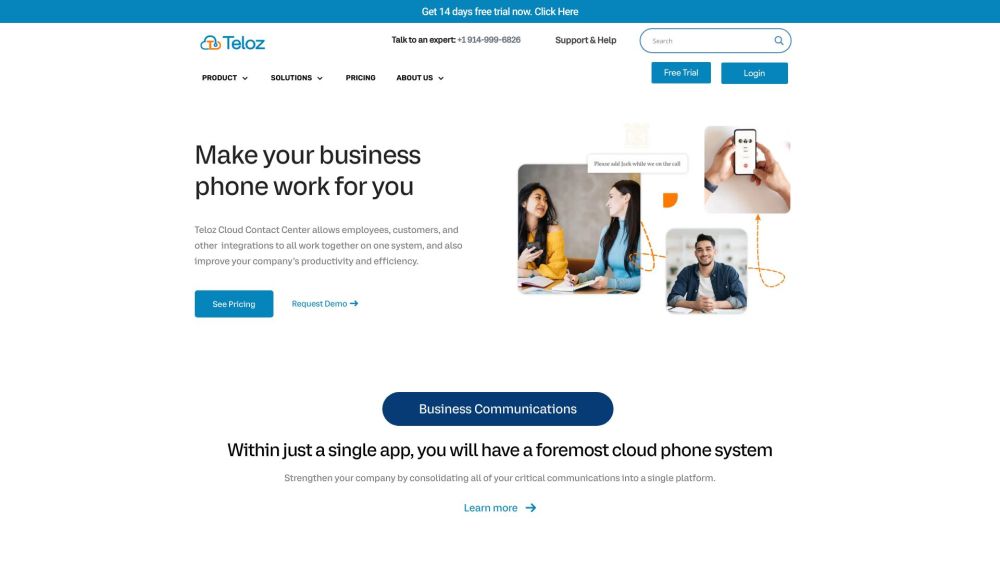
Teloz propose des solutions de communication basées sur le cloud à la pointe de la technologie, dotées de fonctionnalités avancées pour une gestion efficace des centres de contact.

Transformez votre contenu vidéo avec un générateur vidéo IA conçu pour produire des vidéos époustouflantes et de haute qualité sans effort. Que vous soyez une entreprise souhaitant améliorer vos supports marketing ou un créateur de contenu cherchant à captiver votre audience, notre technologie IA avancée simplifie la production vidéo. Découvrez comment vous pouvez élever votre narration et engager vos spectateurs comme jamais auparavant grâce à notre outil innovant de génération vidéo.
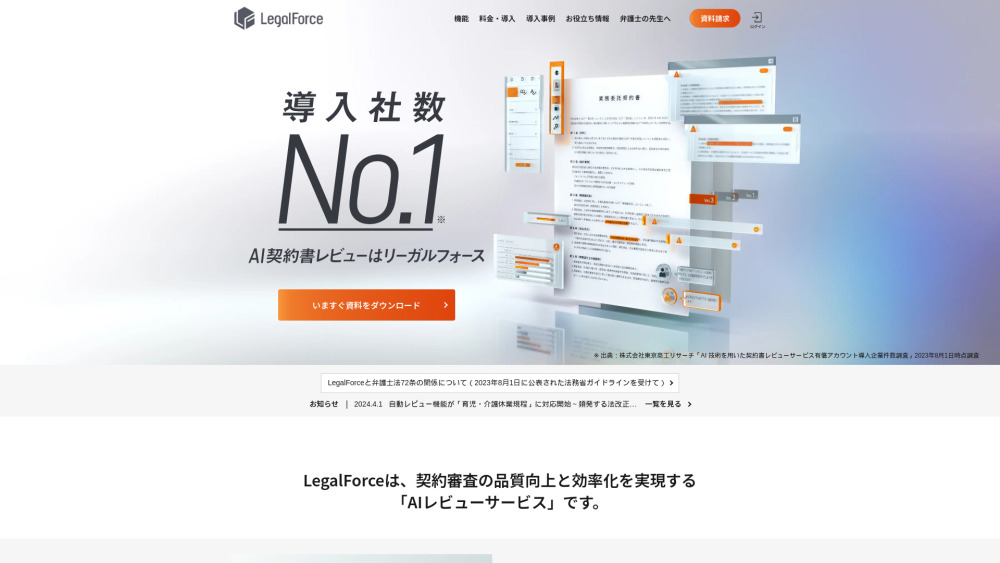
Améliorez votre processus d'examen des contrats avec notre plateforme d'IA : Augmentez la qualité et l'efficacité
Dans le monde des affaires d'aujourd'hui, assurer l'exactitude et l'efficacité des examens de contrats est essentiel. Notre plateforme d'IA innovante est conçue pour améliorer de manière significative la qualité de l'analyse des contrats tout en rationalisant le processus de révision. Découvrez comment l'utilisation d'une intelligence artificielle avancée peut transformer votre gestion de contrats, vous faisant gagner du temps et réduisant les erreurs. Adoptez l'avenir de l'examen des contrats avec une efficacité et une performance sans pareil.
Find AI tools in YBX
Related Articles
Refresh Articles