Llama 3 de Meta AI Crash toutes les 3 heures sur 16 384 GPU H100 : Analyse des problèmes de performance et solutions.
Most people like
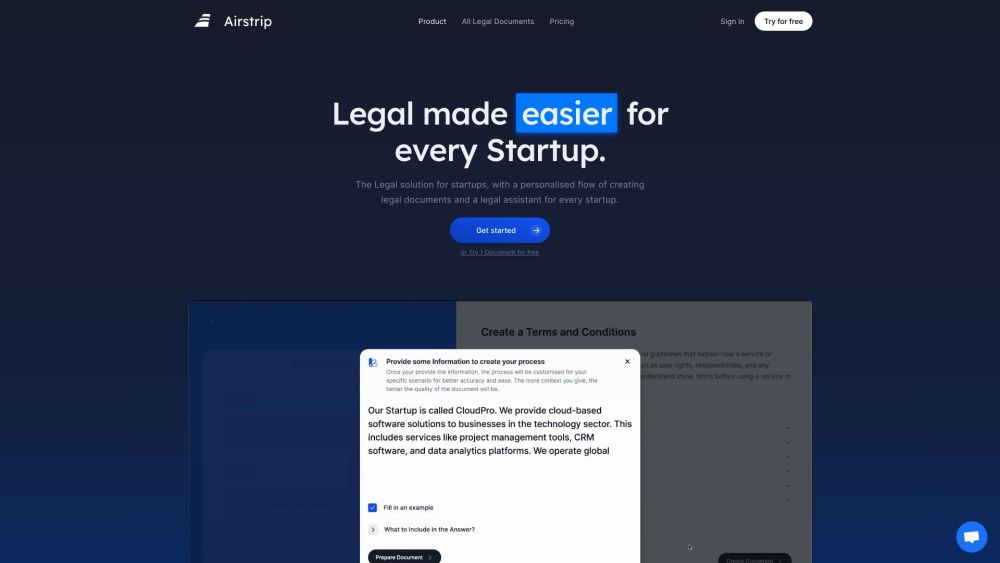
Présentation d'un co-pilote légal alimenté par l'IA, conçu spécifiquement pour les startups. Naviguez dans les complexités des exigences légales avec aisance et confiance.
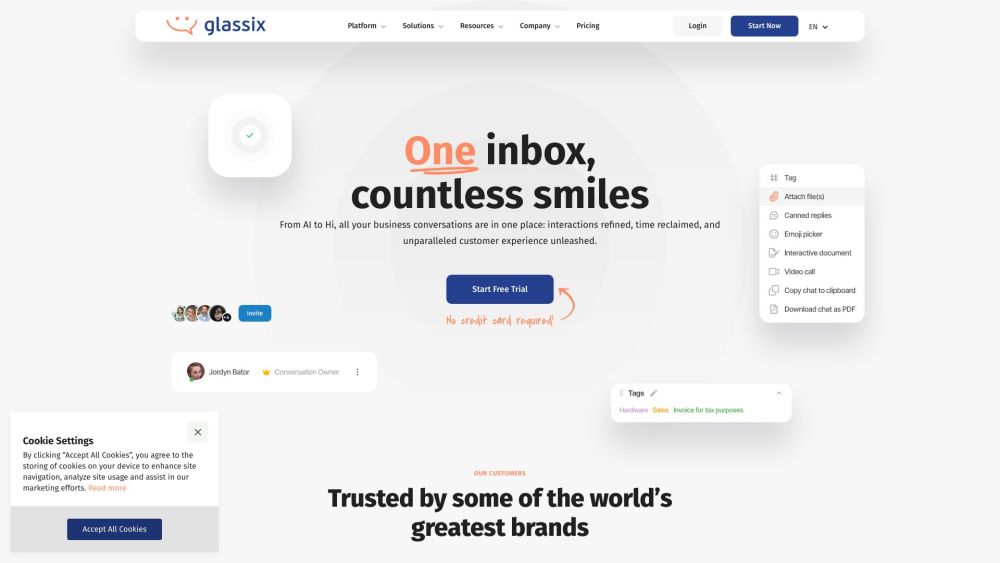
Découvrez la puissance d'une plateforme de messagerie unifiée pilotée par l'IA qui révolutionne la communication des entreprises. Avec une intégration fluide sur plusieurs canaux, cette solution à la pointe de la technologie améliore la collaboration et augmente la productivité. Profitez d'une connectivité en temps réel, de flux de travail simplifiés et d'interactions personnalisées, le tout dans une interface intuitive. Adoptez l'avenir de la messagerie avec un système intelligent conçu pour élever votre stratégie de communication et favoriser votre succès.
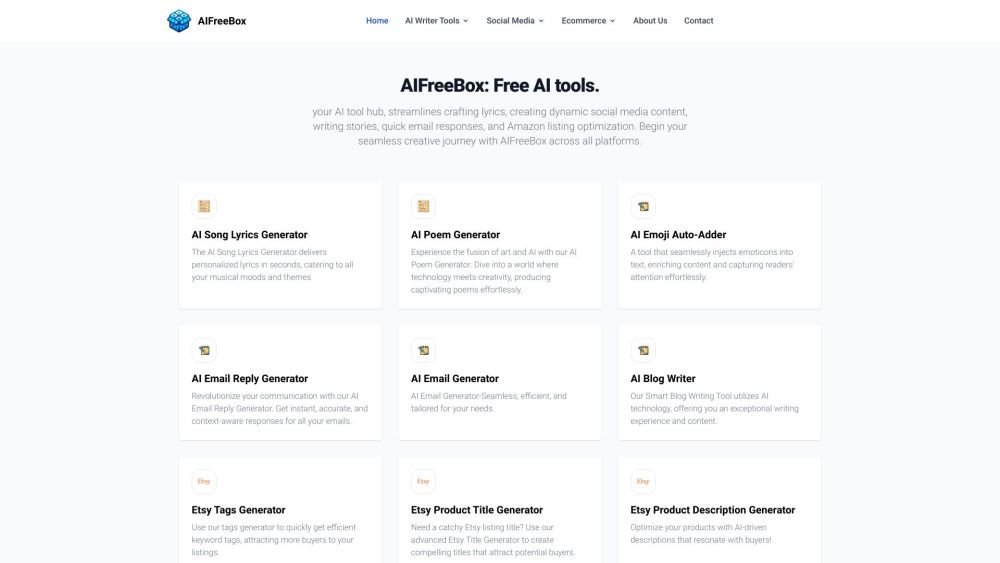
Découvrez le centre ultime d'outils d'IA conçu spécialement pour les projets créatifs. Explorez une gamme variée d'outils innovants qui vous permettent d'améliorer vos réalisations artistiques, d'optimiser votre flux de travail et de libérer votre potentiel créatif. Que vous soyez designer, écrivain ou créateur de contenu, notre plateforme offre tout ce dont vous avez besoin pour élever votre travail et inspirer votre imagination.
Find AI tools in YBX
Related Articles
Refresh Articles