Apple Clarifies: YouTube Resources Used for AI Training, Not Applied to Apple Intelligence
Most people like

Unlock the potential of advanced image recognition technology with our powerful API designed for efficient tagging, seamless categorization, and accurate face recognition. Whether you're looking to enhance your applications or streamline your image processing workflow, our API provides the tools you need to elevate user experiences and improve organizational efficiency. Transform how you manage visual content with cutting-edge solutions tailored to meet your unique needs.
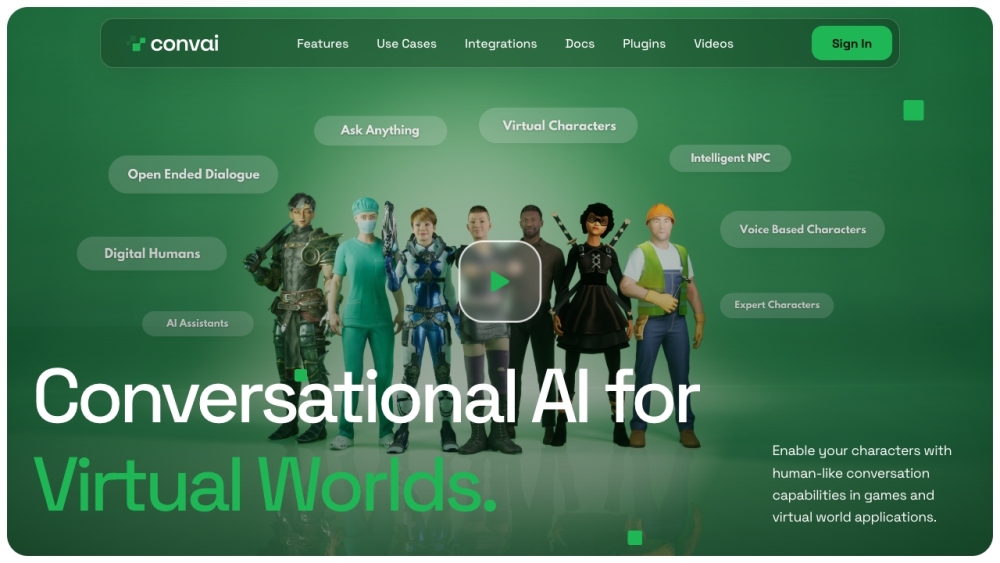
Convai elevates user engagement and crafts immersive experiences through advanced conversational AI tailored for virtual worlds.
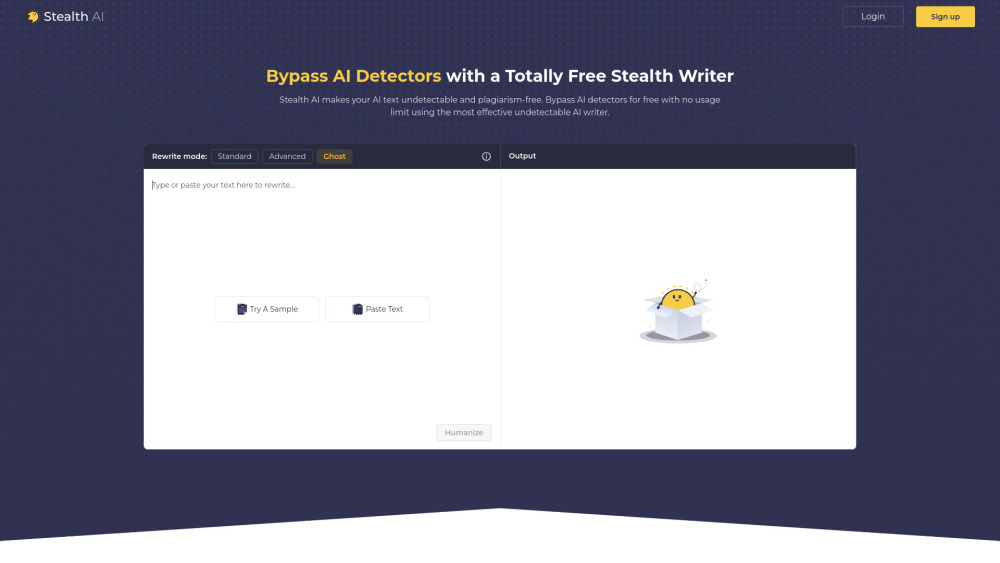
Introducing our cutting-edge AI writer designed to produce plagiarism-free content that goes undetected. Experience the power of advanced technology that ensures originality and creativity in every piece, catering to your unique writing needs while enhancing your online presence. Discover how our undetectable AI writer can elevate your content strategy effortlessly.

Introducing Roam Around, the AI travel assistant that creates tailor-made itineraries to elevate your travel planning experience. Let Roam Around take the hassle out of organizing your trips, ensuring a seamless journey from start to finish.
Find AI tools in YBX
Related Articles
Refresh Articles