Exploring Apple's New 'MM1' AI Model: Features, Applications, and Innovations
Most people like
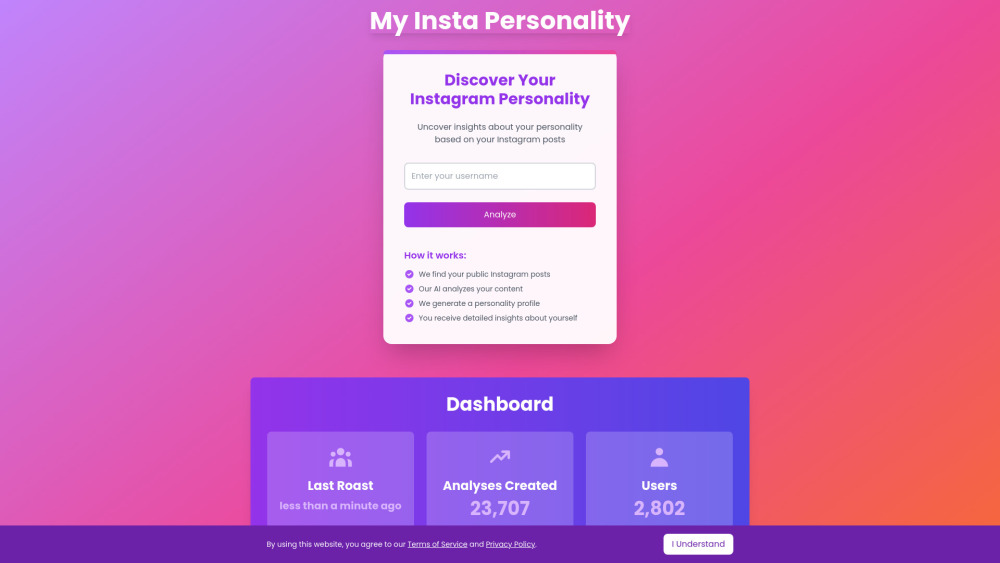
Discover how our AI tool delves into Instagram profiles to uncover unique personality insights. By analyzing user content and interactions, we provide a deeper understanding of individuals’ traits and preferences. Unlock the potential of social media data with our innovative approach to personality analysis.
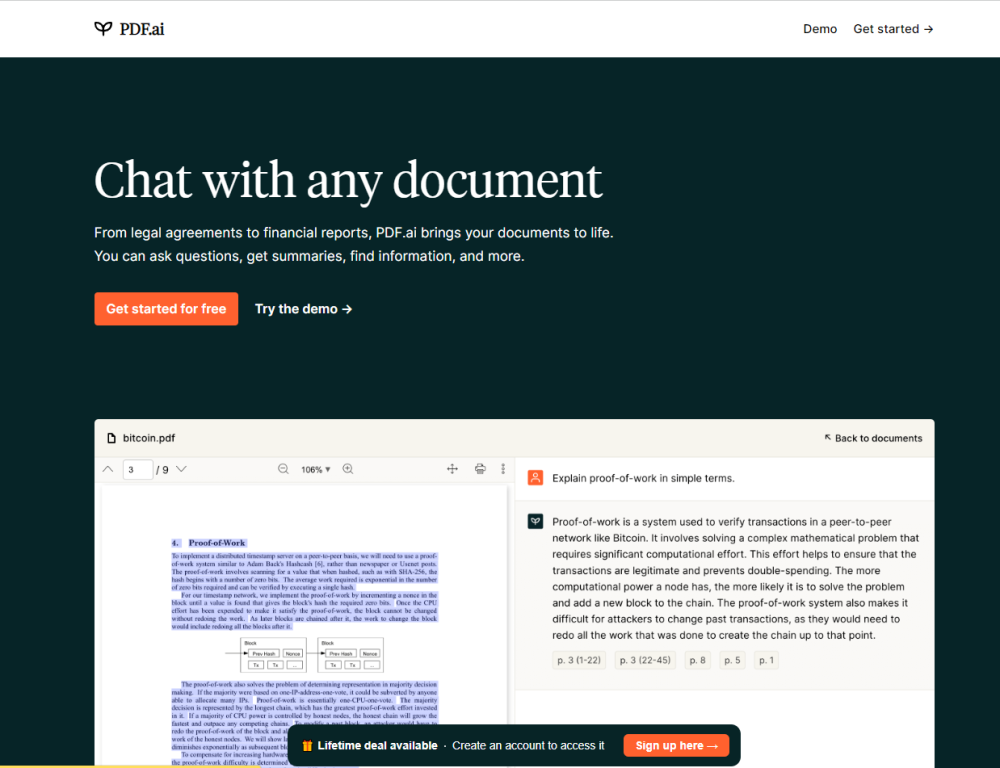

MindPal: An AI-driven platform designed for professionals seeking to boost productivity through a wide array of innovative features. Discover how MindPal can transform your workflow and elevate your performance.
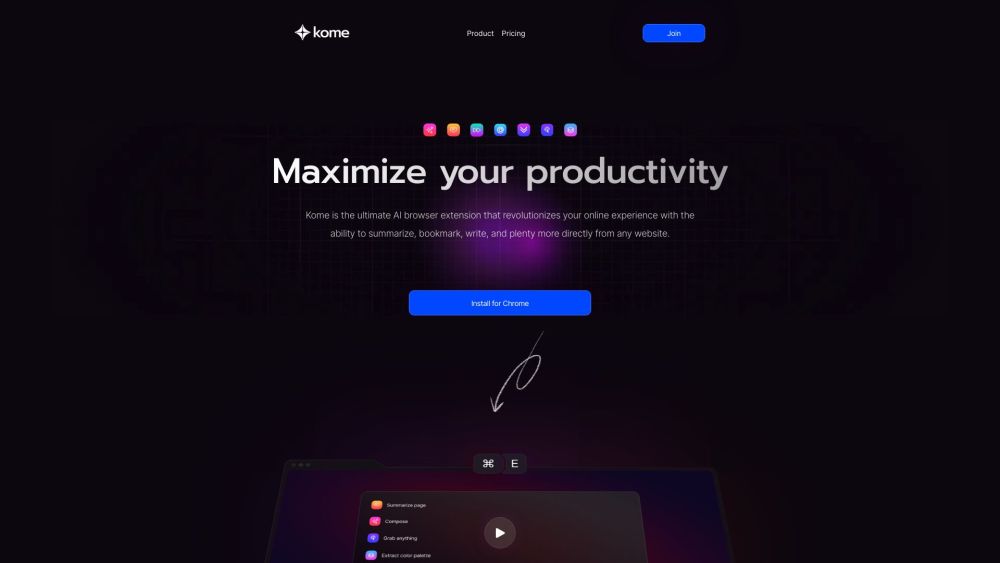
Kome is an innovative browser extension that enriches your online browsing experience by integrating AI-driven tools for enhanced functionality and convenience.
Find AI tools in YBX
