Frequent Training Failures of Llama 3: Analysis of 16384 H100 GPU Cluster 'Strikes' Every 3 Hours
Most people like
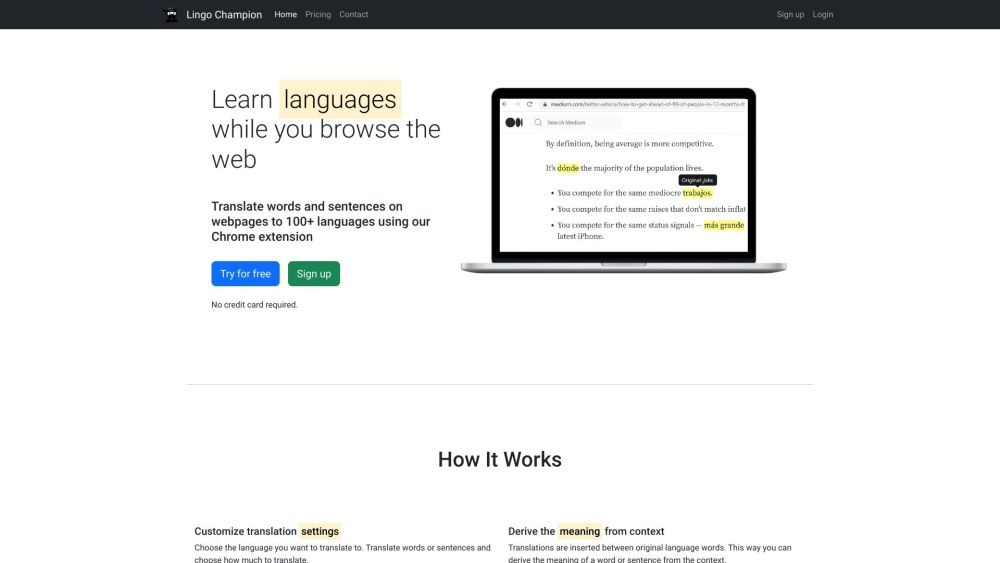
Discover the joy of learning languages effortlessly as you browse the web with Lingo Champion! Enhance your skills in real-time without interrupting your online experience.
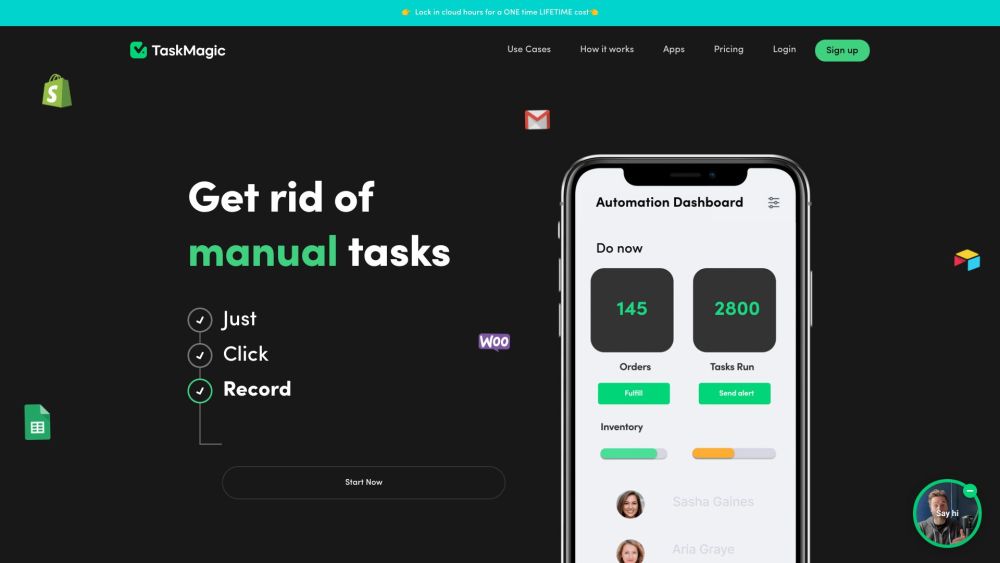
In today’s fast-paced world, the ability to efficiently streamline processes is more crucial than ever. By recording your efforts just once, you can set up automated systems that continually work for you, saving time and reducing manual tasks. Embrace this powerful approach to enhance productivity and focus on what truly matters.
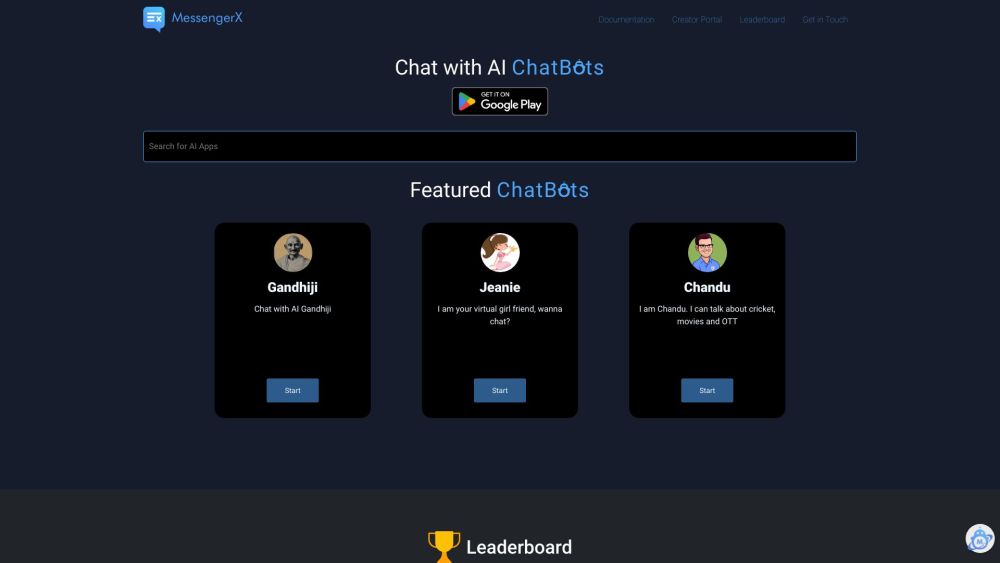
MessengerX.io is an innovative AI chat application designed to connect users with intelligent chatbots. Experience seamless interactions and explore the potential of AI-driven conversations today!
Discover the world’s leading AI coach designed specifically for mental health support.
Find AI tools in YBX
Related Articles
Refresh Articles