新たな人間性研究が明らかにしたAIシステム内の隠れた「スリーパーエージェント」
Most people like
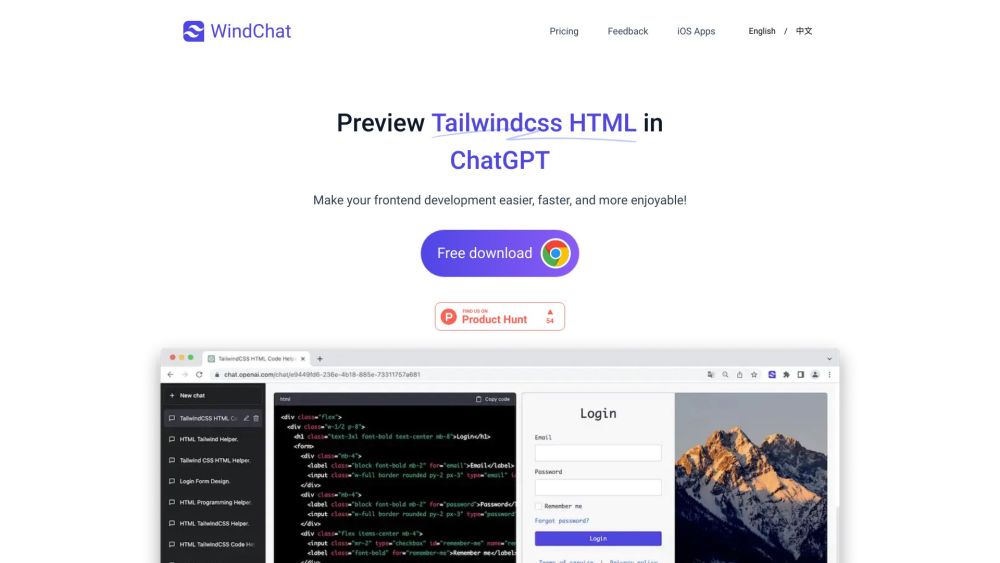
ChatGPT内でTailwind CSSのHTMLコードをシームレスにプレビューする方法を発見しましょう。ウェブデザイン体験を向上させ、この効果的なアプローチでワークフローを効率化します。初心者にも経験豊富な開発者にも、このガイドはTailwind CSSの力を活用し、ChatGPTと共に生産性と創造性を高める手助けをします。ぜひ、詳しく学びましょう!
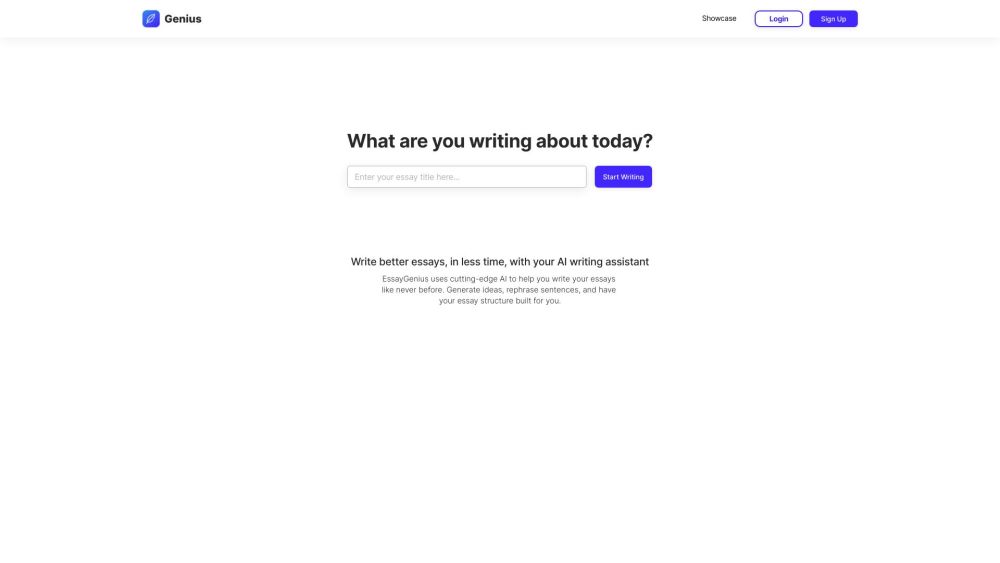
EssayGeniusは、高品質なエッセイを迅速かつ効率的に作成するために設計された革新的なAIプラットフォームです。先進的な技術を活用し、執筆プロセスを効率化することで、短時間で印象的なコンテンツを生み出すことができます。

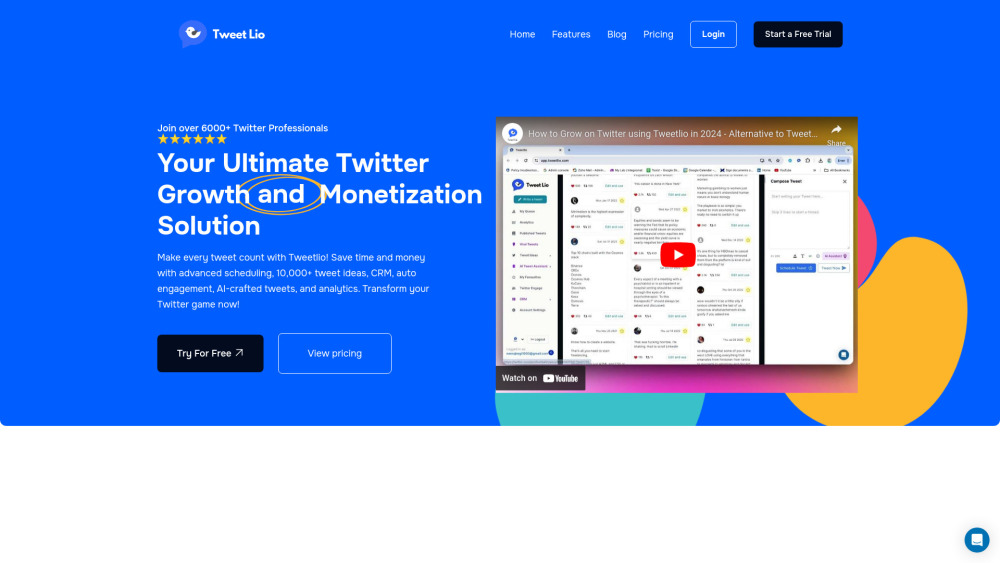
Twitterのスケジュール管理を効率化し、エンゲージメントを向上させる究極のAIツールを発見してください。個人や企業に最適なこの革新的なソリューションは、投稿を整理するだけでなく、最大限のインタラクションを実現するために最適化します。Twitterでつながるスマートな方法を体験し、オンラインプレゼンスを引き上げましょう。
Find AI tools in YBX
Related Articles
Refresh Articles