Cohere for AIが101言語をサポートするオープンソースLLMを発表:グローバルなAIコミュニケーションを促進
Most people like

あなたの個人的なAIチャットボット、Gita GPTをご紹介します。Gita GPTは、バガヴァット・ギーターからの霊的な洞察を提供します。Gita GPTと共に深い教えを探求し、あなたの質問に対する答えを見つけることで、霊的な旅を豊かにしましょう。
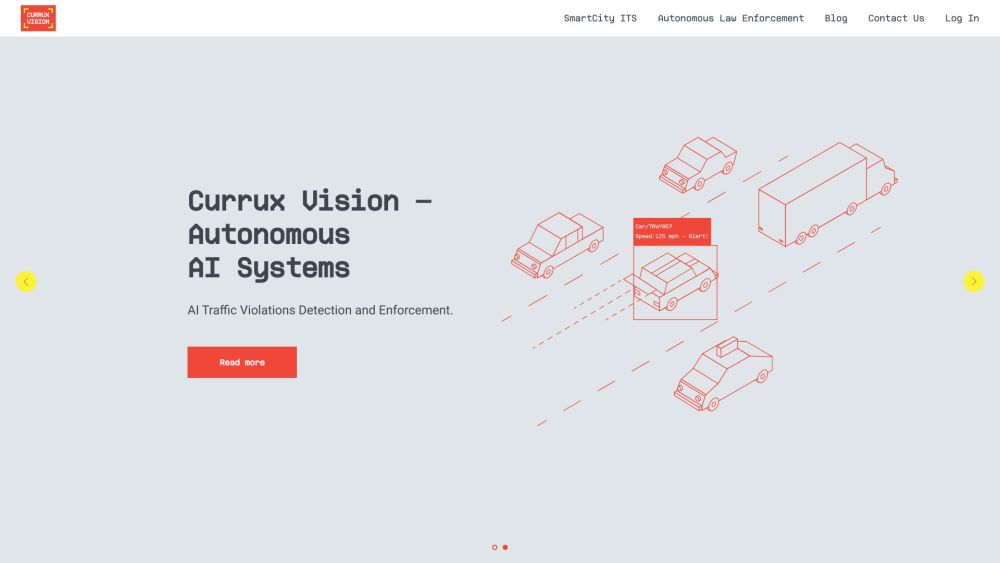
Currux Visionは、インテリジェントインフラ向けに設計された高度なAIシステムを開発し、さまざまなプロジェクトの監視、最適化、収益化を可能にします。最先端の技術を活用することで、プロジェクトの効率を向上させ、よりスマートな未来のための革新的な解決策を推進します。
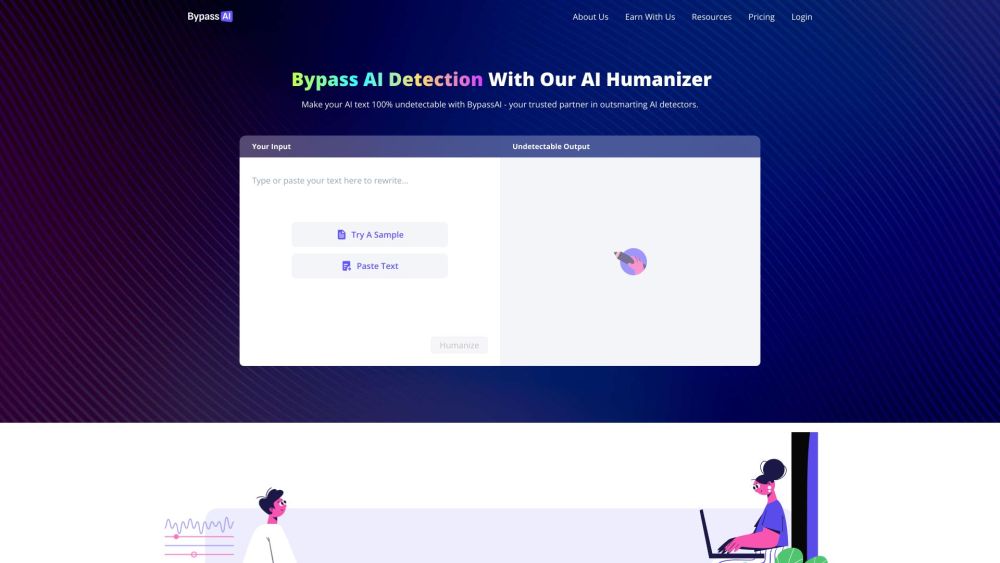
AI生成テキストを完全に見えなくする秘密を解き明かしましょう。人間と機械生成コンテンツの境界が曖昧になる今日のデジタル環境では、AIの文章が本物の人間の表現とシームレスに融合するためのテクニックを習得することが不可欠です。SEO、クリエイティブプロジェクト、またはプロフェッショナルな目的でコンテンツを強化したい場合でも、このガイドはAIテキストを不可視化するための実践的な戦略を提供します。あなたのライティングアプローチを変革し、コンテンツの信頼性を高める準備を整えましょう!
Find AI tools in YBX
Related Articles
Refresh Articles