MLPerf 4.0 トレーニング結果: AIパフォーマンス向上を最大80%達成!
Most people like
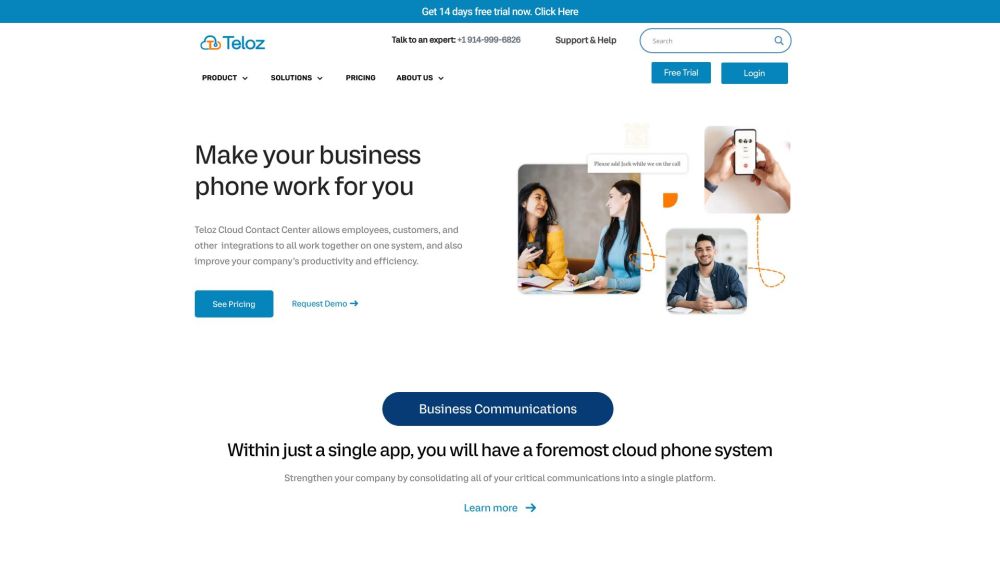
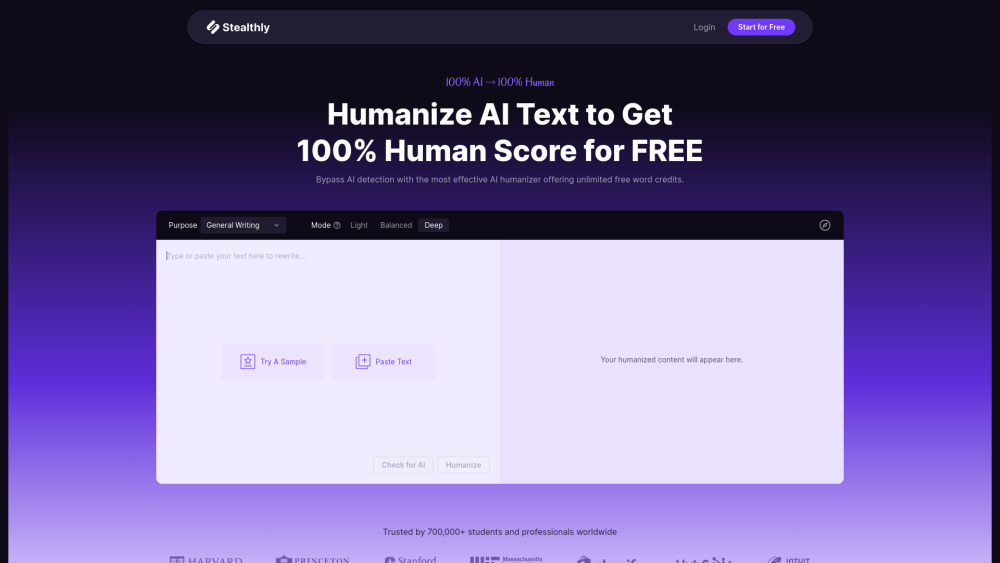
今日のデジタル環境において、読者に響く高品質なコンテンツを作成することは不可欠です。AIテキストヒューマナイザーは、AI生成のテキストをより自然で人間らしい言語に変換するための強力なツールです。この技術は、コンテンツが魅力的で本物であることを保証し、機械生成であることがほとんど認識されません。AIテキストヒューマナイザーを活用することで、執筆の可読性や感情的な影響を高め、最終的にはユーザー体験を向上させたり、SEOランキングを向上させたりすることができます。AIテキストヒューマナイザーと共にコンテンツ制作の未来を受け入れ、あなたの作品を新たな高みに引き上げましょう。

高度なテキストから画像へのモデルを紹介します。このモデルは、視覚コンテンツ作成における画像の忠実度と精度を向上させるよう設計されています。この革新的な技術は、最先端のアルゴリズムを駆使してテキストの説明を驚くべき高品質な画像に変換し、すべての詳細が意図したビジョンと完璧に調和することを保証します。明瞭さと芸術的表現の新たな基準を打ち立てる、洗練されたモデルによるビジュアルストーリーテリングの未来を体験してください。
AI駆動のソリューションが、顧客と社内チームのサポート体験をどのように変革するかを発見しましょう。プロセスを自動化し、リアルタイムの支援を提供することで、AIは迅速な対応を強化し、顧客満足度の向上と効率的な運営を実現します。ユーザーとチームメンバーのニーズに応える知能的なツールを使って、サポートの未来を受け入れましょう。
Find AI tools in YBX
