OpenAIのSora: その革新を支える「データの詳細」を解明する
Most people like
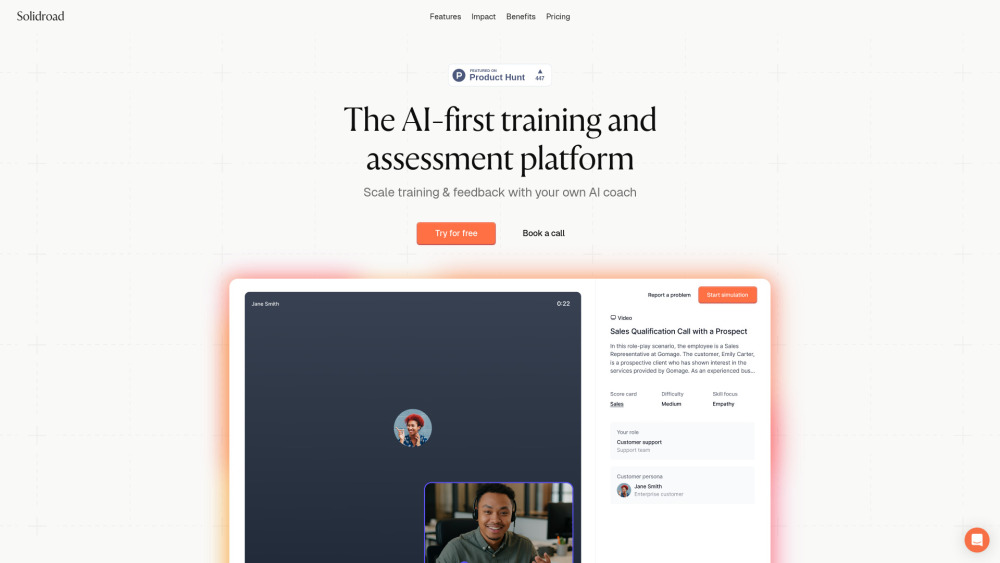
トレーニングの革命:顧客対応チームのためのAI駆動プラットフォーム
最先端のAI搭載トレーニングプラットフォームで、顧客対応チームの可能性を引き出しましょう。スキルとパフォーマンス向上を目的とした本ソリューションは、スタッフに顧客対応で卓越するためのツールを提供します。今日のダイナミックな市場に合わせた革新的なトレーニング方法を通じて、比類のない成長と顧客満足を体験してください。

AIを活用したロールプレイで営業パフォーマンスを向上させる
革新的なAI駆動のロールプレイ戦略で、営業チームの潜在能力を引き出しましょう。実際のシナリオをシミュレーションすることで、これらのインタラクティブなツールは貴重なフィードバックを提供し、コミュニケーションスキルを向上させます。その結果、営業成功が促進されます。トレーニングにAI技術を統合することで、営業アプローチがどのように変革され、測定可能な成果を導くのかを探ってみましょう。

今日の競争が激しい市場において、AI技術の活用は顧客とのインタラクションを向上させたい企業にとって不可欠です。AIソリューションを統合することで、企業はコミュニケーションを効率化し、体験をパーソナライズし、最終的には顧客満足度を高めることができます。AI駆動の戦略を導入することで、顧客エンゲージメントのアプローチがどのように変革され、長期的な関係を築けるかを探ってみましょう。
Find AI tools in YBX
