OpenAI, 'AI 위험 모니터링 및 감소를 위한 준비 프레임워크' 공개
Most people like
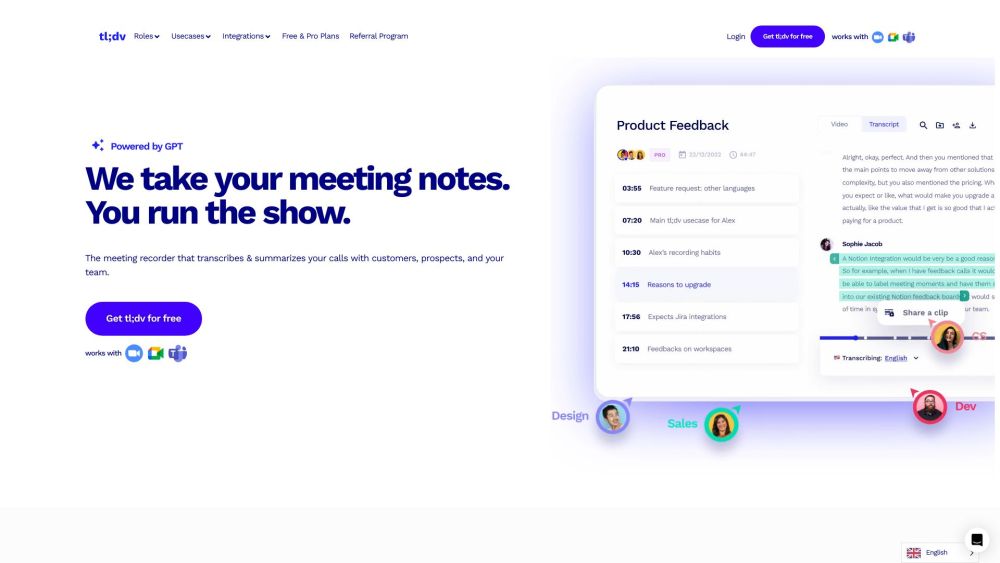
Zoom 및 Google Meet에 특별히 설계된 혁신적인 AI 기반 회의 녹음기를 소개합니다. 중요한 논의를 손쉽게 기록하고 전사하여 가상 협업 경험을 향상시키세요.
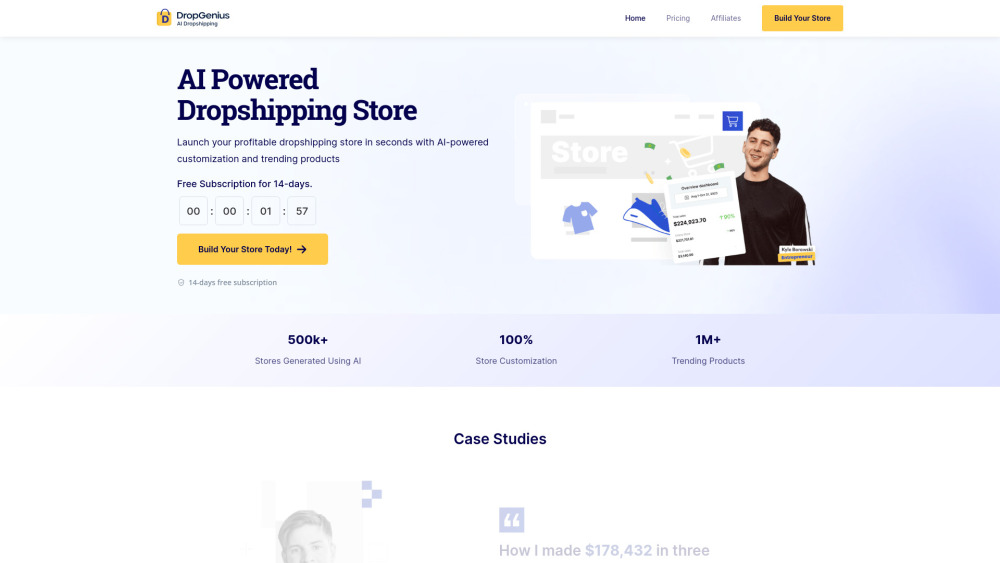
우리의 AI 기반 드롭쉽핑 스토어 플랫폼의 혁신적인 기능을 탐험해 보세요. 온라인 소매 운영을 간소화하도록 설계된 이 혁신적인 솔루션은 기업가들이 제품 소싱, 고객 상호작용 및 재고 관리를 손쉽게 처리할 수 있도록 도와줍니다. 최첨단 기술을 활용하여 효율성을 극대화하고 운영 비용을 줄이며 고객의 쇼핑 경험을 향상시키세요. 전자 상거래의 미래를 수용하고, 우리의 직관적이고 사용하기 쉬운 플랫폼과 함께 비즈니스의 성장을 지켜보세요.
Find AI tools in YBX
Related Articles
Refresh Articles