OpenAI SearchGPT 공식 데모에서 발견된 취약점: 소스 코드와 검색 메커니즘의 비밀 밝혀내기
Most people like
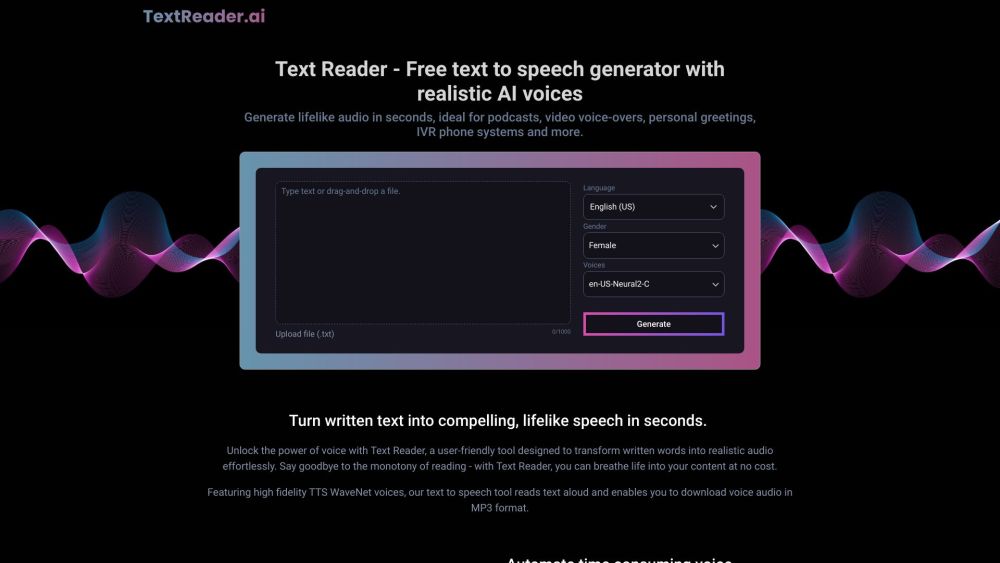

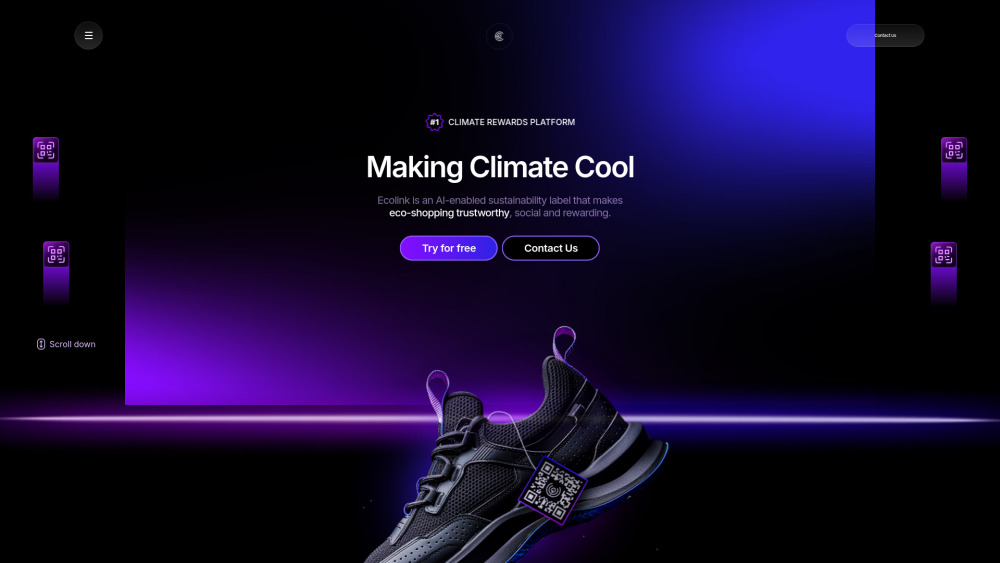
환경 관리 접근 방식을 혁신적으로 변화시키기 위해 설계된 혁신적인 AI 및 블록체인 지속 가능성 플랫폼을 소개합니다. 인공지능과 블록체인 기술의 힘을 활용함으로써, 이 플랫폼은 투명성을 높이고, 효율성을 증대시키며, 다양한 산업 전반에 걸쳐 지속 가능한 관행을 촉진하는 것을 목표로 합니다. 최첨단 기술을 통해 지속 가능성의 미래를 함께 변화시켜 나갑시다.
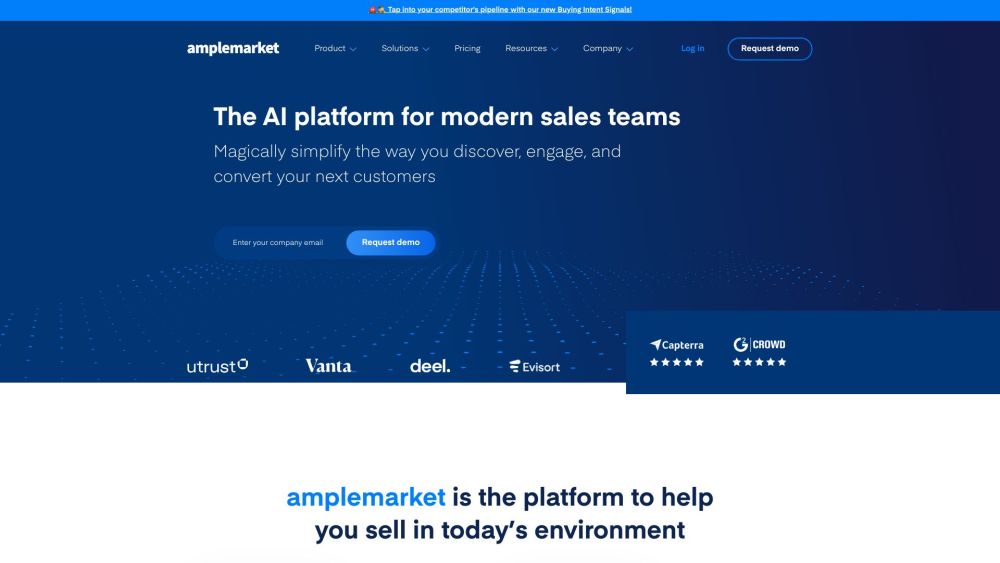
오늘날의 영업 팀을 위해 맞춤 설계된 궁극적인 AI 플랫폼을 소개합니다. 효율성을 높이고 생산성을 증대시키기 위해 설계된 이 혁신적인 솔루션은 인공지능을 활용하여 프로세스를 간소화하고, 워크플로를 최적화하며, 고객 참여를 강화합니다. 귀하의 팀이 뛰어난 성과를 달성할 수 있도록 지원하는 첨단 기술로 영업 전략을 혁신하세요.
Find AI tools in YBX
Related Articles
Refresh Articles