애플의 설명: 유튜브 자료는 AI 훈련에 사용되었으며, 애플 인텔리전스에는 적용되지 않음.
Most people like
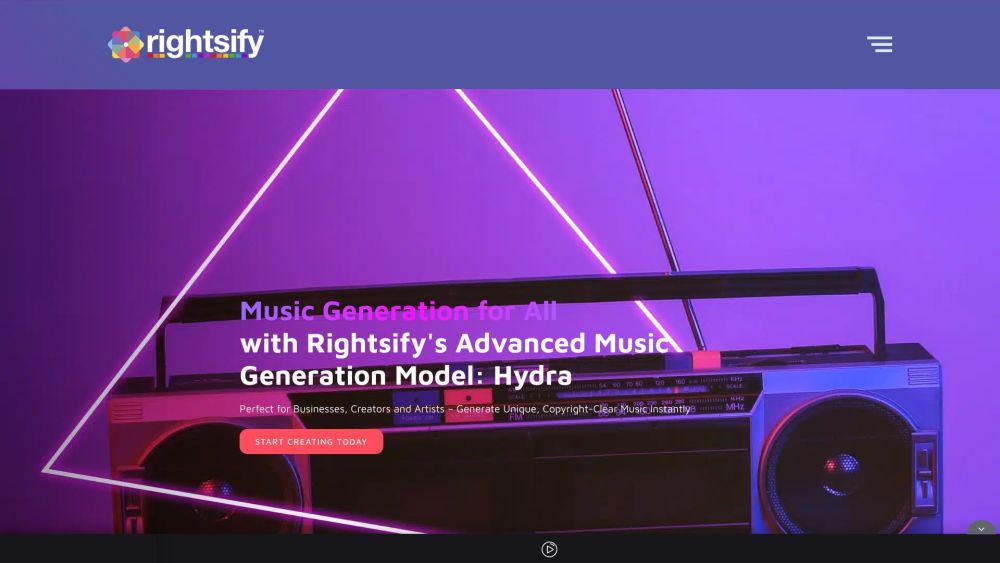
AI 음악 생성의 세계를 발견하세요. 최첨단 기술이 여러분의 필요에 맞춘 독특한 기악 음악과 매혹적인 음향 효과를 만들어냅니다. 인공지능이 음악 작곡을 혁신하는 과정을 경험하며, 독창적인 오디오를 원하는 예술가, 영화 제작자, 콘텐츠 제작자들을 위한 혁신적인 솔루션을 제공합니다.

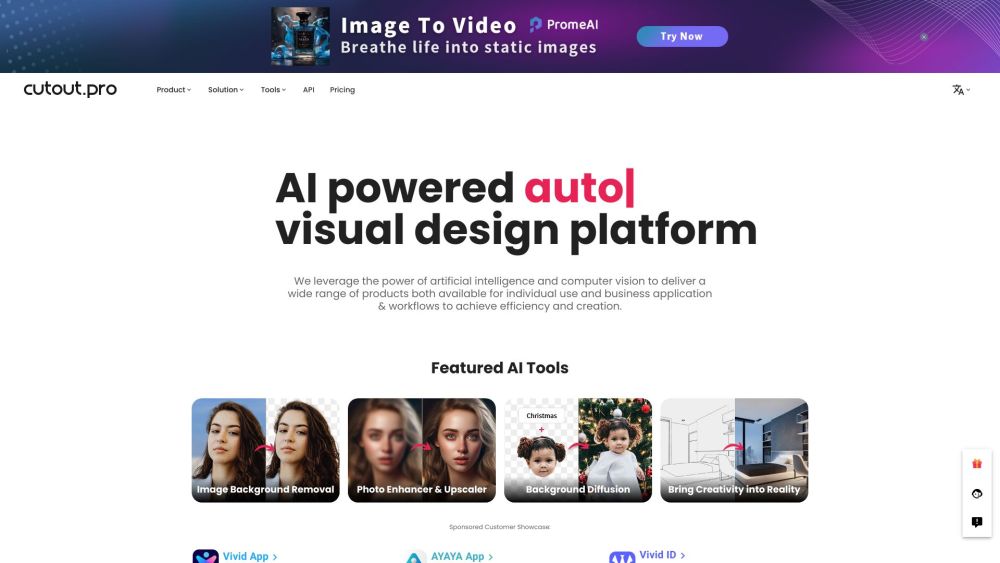
우리의 AI 기반 사진 편집 및 콘텐츠 생성 플랫폼의 힘을 경험해 보세요. 최첨단 기술을 손쉽게 활용하여 이미지를 향상시키고 눈길을 사로잡는 콘텐츠를 만들어 보세요. 오늘부터 여러분의 시각적 스토리텔링 경험을 혁신해 보세요!
Find AI tools in YBX
Related Articles
Refresh Articles