Grande Avanço no Projeto LLaVA++: Aprimorando as Capacidades Visuais dos Modelos Phi-3 e Llama-3
Most people like

Symph AI oferece soluções inovadoras de inteligência artificial projetadas para aprimorar processos de tomada de decisão e acelerar ciclos de desenvolvimento.
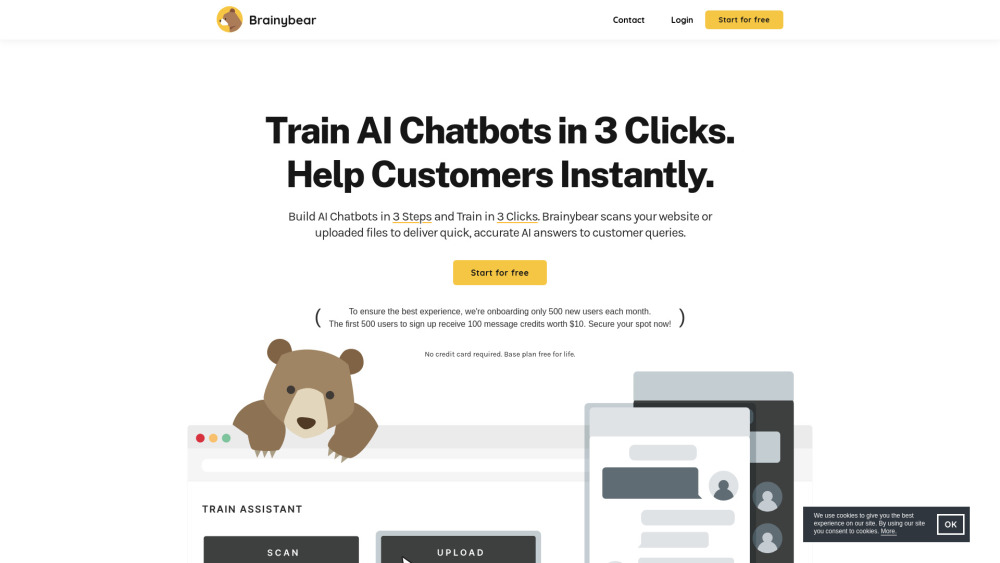
Apresentamos uma plataforma de chatbot com IA, projetada para a criação fácil e o treinamento contínuo de chatbots. Otimize suas interações com os clientes e melhore o engajamento dos usuários com uma interface intuitiva que capacita qualquer pessoa a desenvolver soluções de chat com IA de forma rápida e eficaz. Seja você um empresário, um profissional de marketing ou um desenvolvedor, esta plataforma simplifica o processo, permitindo que você aproveite o poder da IA para aprimorar suas estratégias de comunicação.
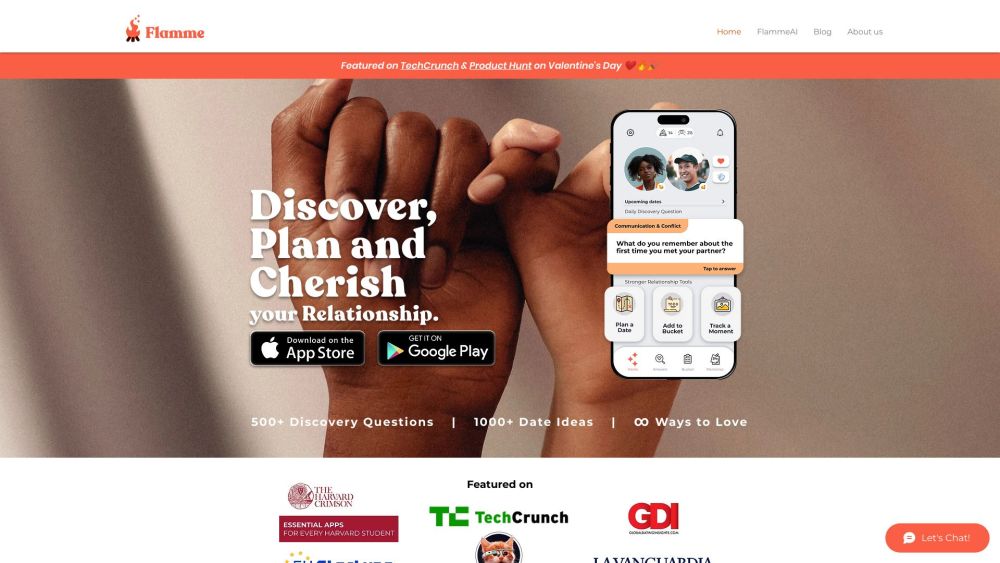
Flamme capacita casais a aprofundar sua conexão por meio de perguntas cuidadosamente elaboradas e ideias únicas para encontros. Descubram mais sobre si mesmos enquanto exploram novas experiências juntos.

Aprimore Sua Experiência de Leitura com Nossa Extensão de Texto para Fala
Descubra uma nova forma de interagir com seus materiais de leitura através da nossa inovadora extensão de texto para fala. Projetada para melhorar a compreensão e a acessibilidade, esta ferramenta transforma conteúdo escrito em áudio claro e com som natural. Seja estudando, trabalhando ou simplesmente desfrutando de um livro, nossa extensão torna a leitura mais fácil e agradável. Liberte o poder da aprendizagem auditiva e eleve suas experiências de leitura hoje mesmo!
Find AI tools in YBX
Related Articles
Refresh Articles