Крупный прорыв в проекте LLaVA++: Улучшение визуальных возможностей моделей Phi-3 и Llama-3
Most people like
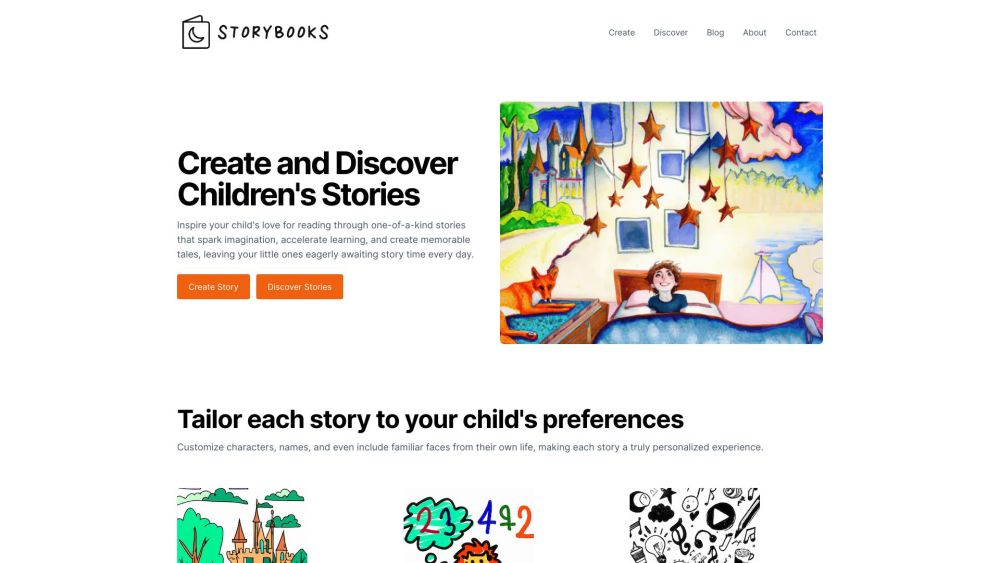
Storybooks — это специализированная платформа, предлагающая персонализированные иллюстрированные книги на ночь, созданные для развития любви к чтению и укрепления связи между родителями и детьми.
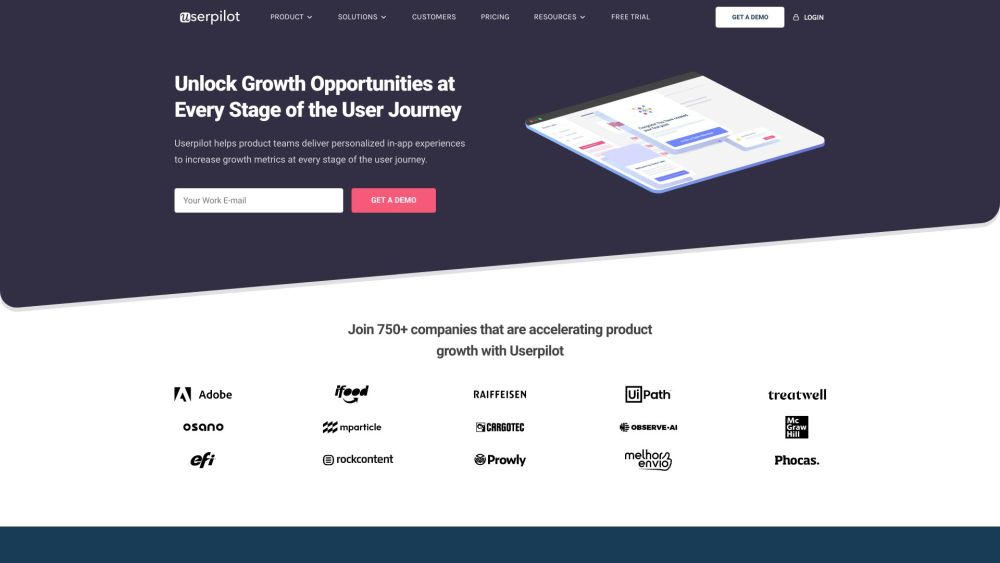
Userpilot — это инновационная платформа для роста продуктов, созданная для повышения пользовательского взаимодействия через персонализированные интерактивные опыты, что способствует значительному росту вашего бизнеса.

Откройте для себя динамичную платформу для фэнтезийных исследований и увлекательных ролевых бесед. Погрузитесь в яркое сообщество, отправляясь в приключенческие путешествия, создавая сложные персонажи и принимая участие в захватывающих сюжетах. Независимо от того, являетесь ли вы заядлым ролевиком или новичком в жанре, наша платформа предоставляет инструменты и ресурсы, предназначенные для улучшения вашего опыта в fantastical мирах вашего воображения. Присоединяйтесь к нам сегодня и дайте волю своему творчеству!
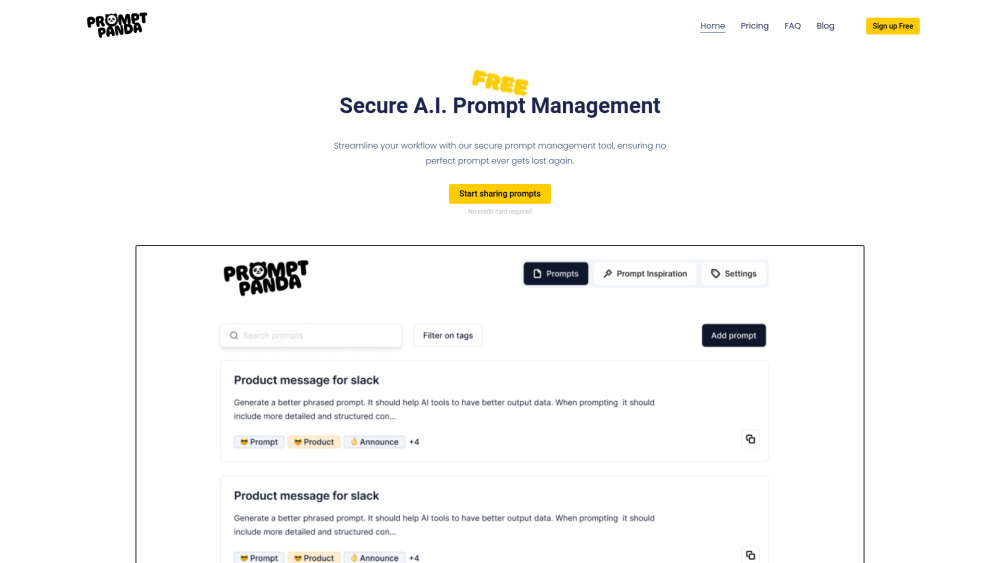
В современном быстром цифровом мире эффективное управление AI-запросами жизненно важно для оптимизации рабочих процессов. Используя мощь искусственного интеллекта, вы можете упростить свои процессы, повысить производительность и улучшить общую эффективность. Этот гид исследует ключевые стратегии и инструменты, которые помогут вам освоить управление AI-запросами, обеспечивая бесперебойную и эффективную работу ваших операций.
Find AI tools in YBX
Related Articles
Refresh Articles