SambaNova запускает модель "Состав экспертов" с 1 триллионом параметров для решений генеративного ИИ в бизнесе.
Most people like
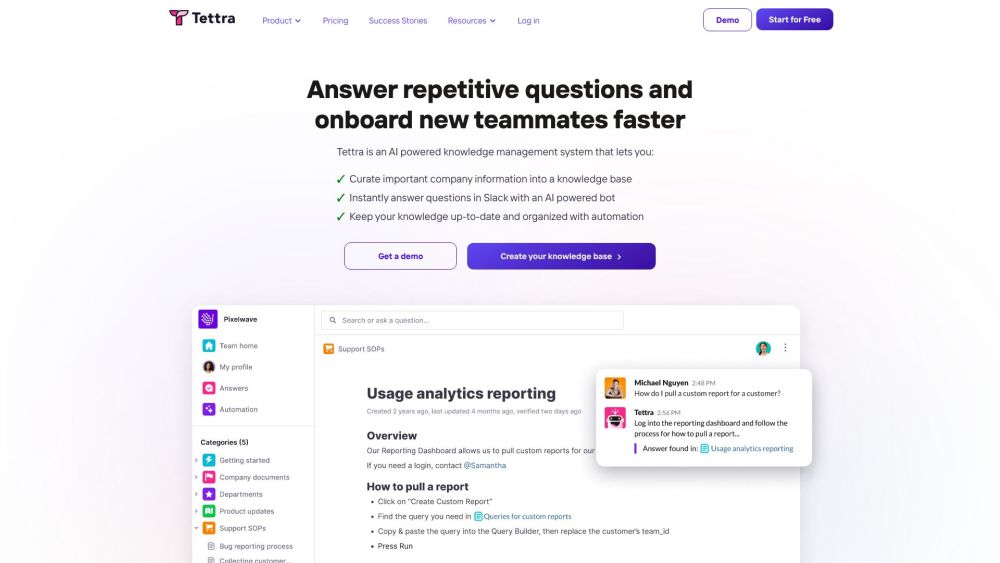
Представляем нашу систему управления знаниями на основе ИИ: революционизируйте способ, которым ваша организация захватывает, организует и получает доступ к информации. Используя передовые технологии искусственного интеллекта, наша система упрощает обмен знаниями, улучшает сотрудничество и увеличивает продуктивность. Узнайте, как наше инновационное решение может преобразовать ваши практики управления знаниями и помочь вашей команде принимать обоснованные решения быстрее и эффективнее. Оптимизируйте свои рабочие процессы и максимально используйте потенциал вашей организации с нашей передовой ИИ-технологией.
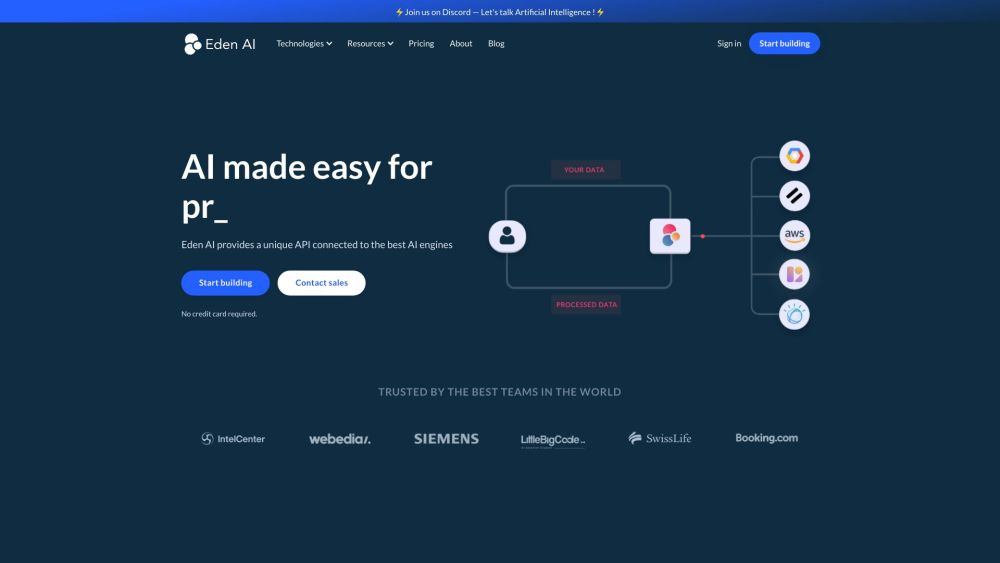
Откройте для себя Eden AI, где мы предлагаем удобный API, который подходит как для разработчиков, так и для непрофессионалов, интегрируя различные технологии ИИ для легкого доступа и инновационных решений.
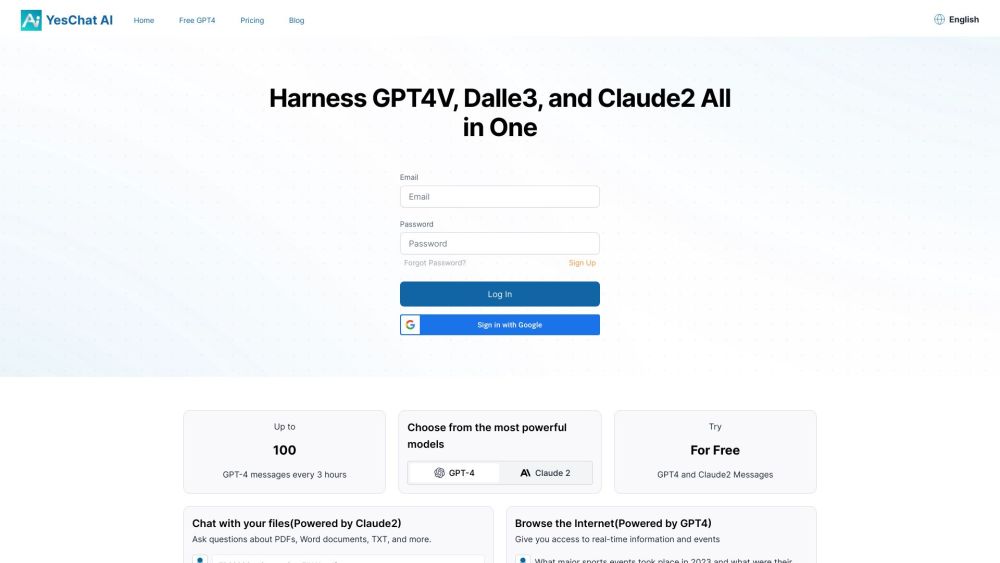
Изучите возможности продвинутых чат-ботов на основе Claude 2, обеспечивающих динамичные и увлекательные беседы совершенно бесплатно.
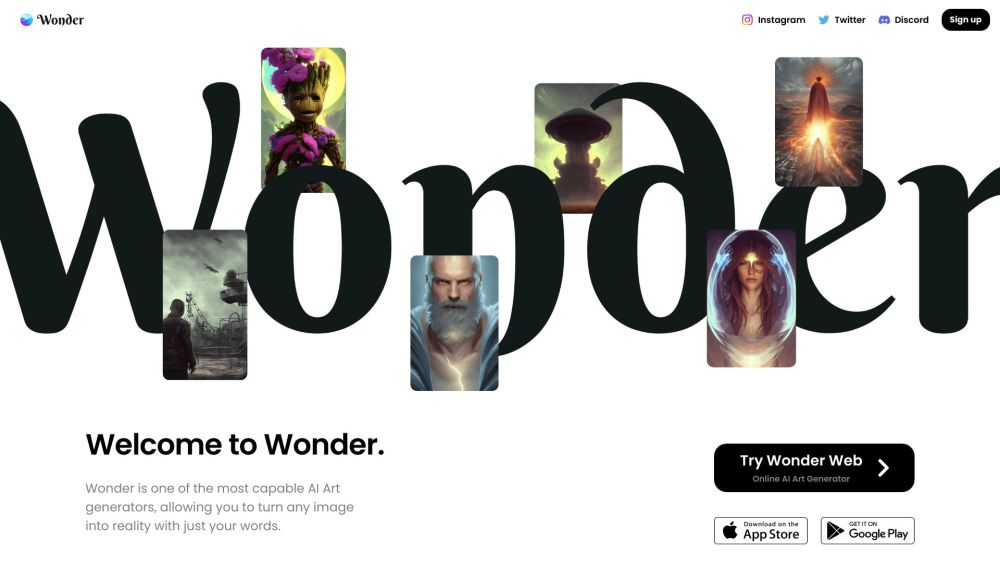
Разблокируйте силу творчества с нашим руководством по преобразованию текста в потрясающее цифровое искусство. Узнайте, как использовать инновационные инструменты и техники, позволяющие превращать слова в завораживающие визуальные образы. Независимо от того, являетесь ли вы начинающим художником или опытным профессионалом, научитесь поднимать свои работы на новый уровень, создавая впечатляющие цифровые дизайны прямо из вашего воображения.
Find AI tools in YBX
Related Articles
Refresh Articles