GAIA基準:下一代人工智慧應對現實世界挑戰
Most people like
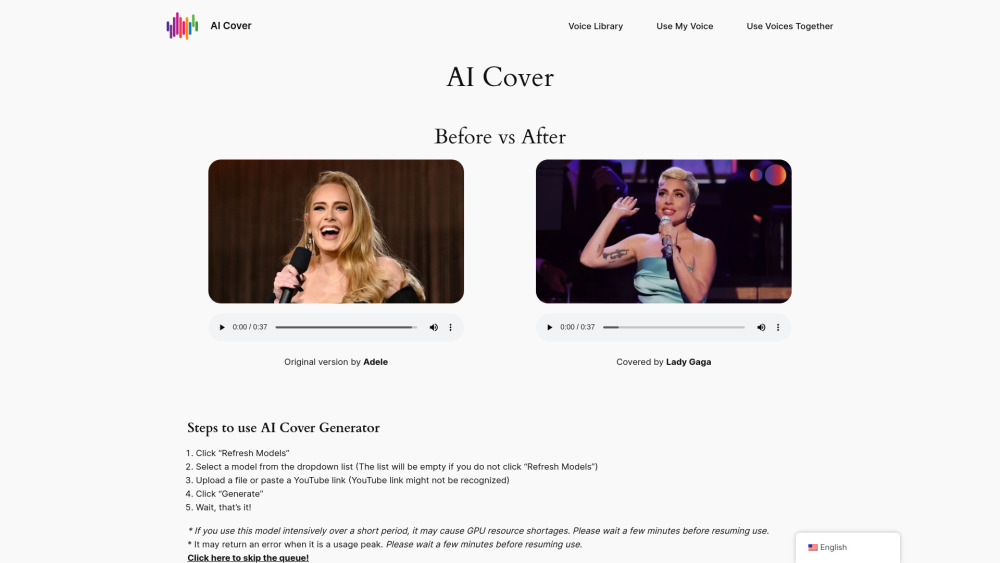
介紹一款創新的 AI 工具,簡化高品質歌曲翻唱的創作過程,讓您輕鬆上手。無論您是經驗豐富的音樂人,還是充滿熱情的初學者,我們的平台都能輕鬆幫助您創造驚人的翻唱作品。
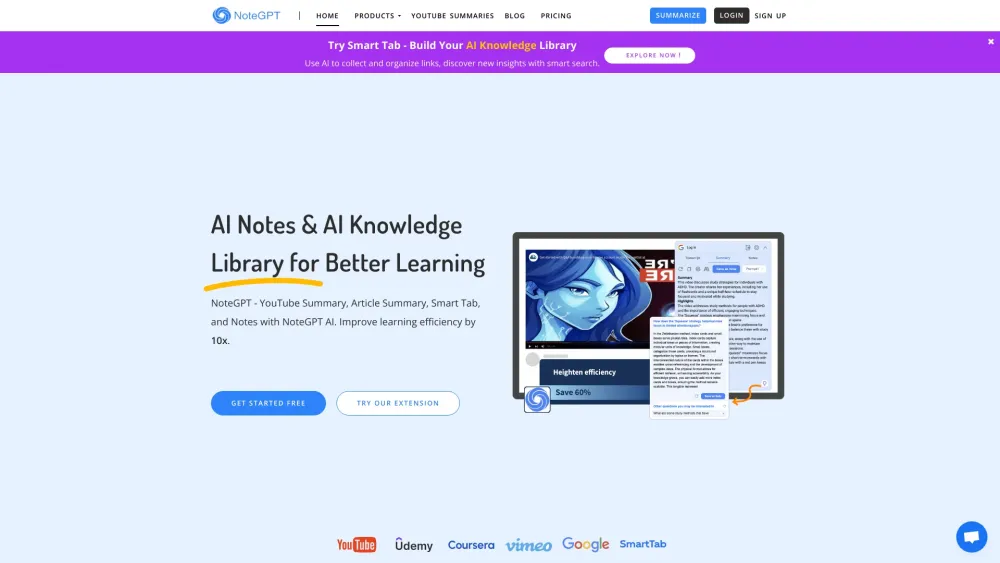
輕鬆自動縮略視頻、文章和文字,運用人工智能技術。與智能AI助手進行對話,以獲取更深入的見解。輕鬆生成文字記錄,自動化您的筆記過程,並有效管理您的資料夾。享受我們為您便利而設計的先進工具帶來的高效生產力。
徹底改變海關申報:全球企業的人工智慧解決方案
在這個日益互聯的世界中,全球企業面臨著複雜的海關申報挑戰。利用尖端的人工智慧解決方案可以簡化海關流程,提高效率和合規性。深入了解這些創新技術如何改變您的業務運營,並輕鬆駕馭國際貿易。
Find AI tools in YBX
Related Articles
Refresh Articles