Google DeepMind:透過增強人際連結提升AI表現
Most people like
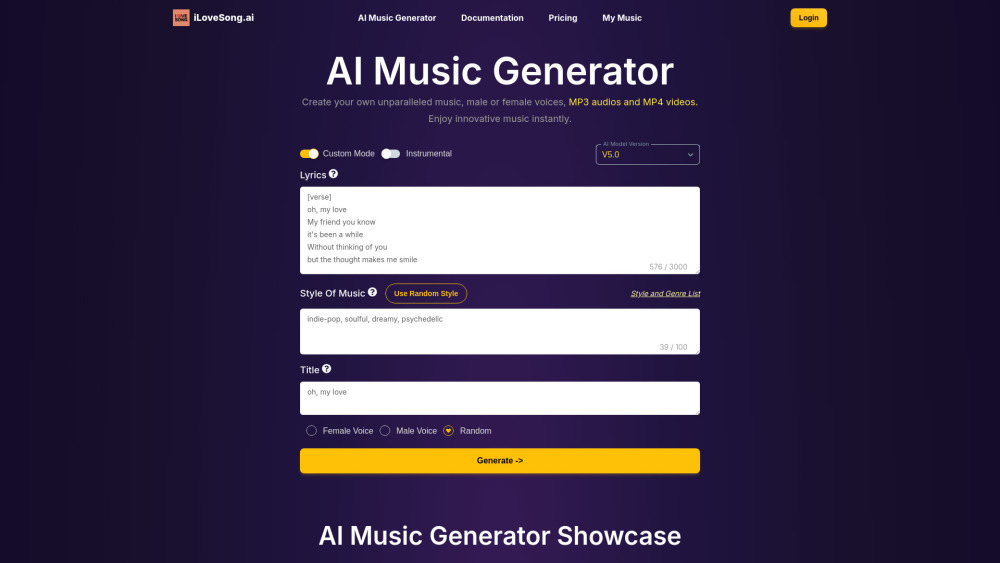
探索我們的AI音樂生成器的力量,旨在幫助您創作和下載獨特的、量身定制的音樂,滿足您的需求。無論您是尋找項目的原創作品、影片的背景音樂,還是個性化的聲音景觀,我們的平台都讓每個人都能輕鬆享受音樂創作的藝術。今天就開始創作您的旋律吧!
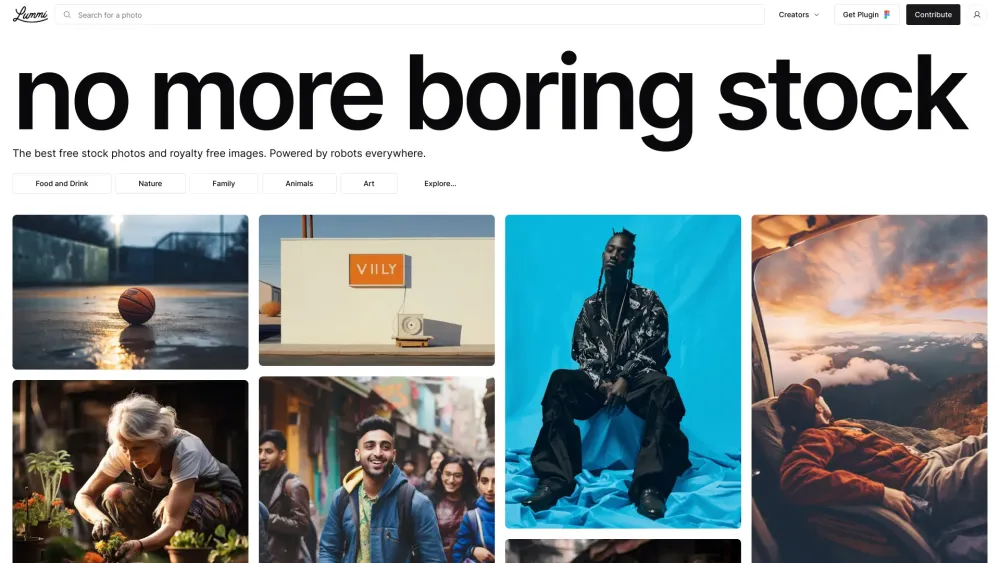
發現由人工智慧精選的股票照片世界,尖端技術與驚豔視覺的完美結合。探索豐富的高品質圖片庫,這些圖片均經過人工智慧精心挑選,以滿足您的創意需求。不論是用於行銷活動、社群媒體或個人專案,我們的人工智慧驅動平台確保您能找到與目標受眾產生共鳴的理想股票照片。今天就沉浸於全新影像時代,為您的專案提升引人注目的視覺效果!

RushChat.ai 提供一個無限制的 NSFW 聊天機器人 AI 服務,使用者可以與自己喜爱的角色扮演 AI 角色進行開放且成人主題的對話。這個平台秉持無審查政策,鼓勵自由且坦率的交流。
Find AI tools in YBX
Related Articles
Refresh Articles