Google DeepMind:透過增強人際連結提升AI表現
Most people like
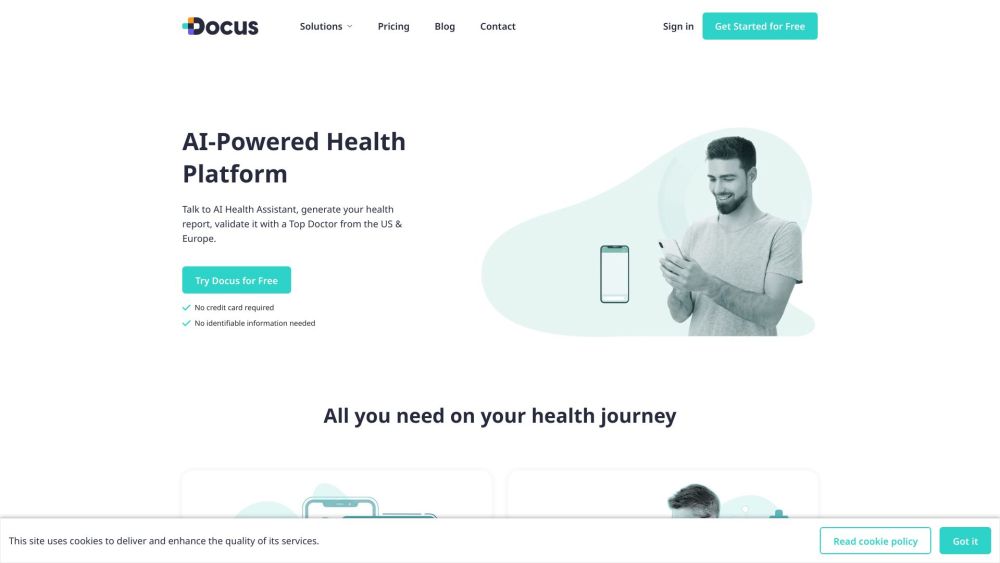
介紹您的人工智慧虛擬健康助理,專為提供個性化建議和支持而設計。這個創新工具結合了先進的人工智慧與豐富的健康專業知識,確保您獲得準確的建議和指導,助您維護健康。今天就來了解我們的虛擬健康助理如何為您的健康旅程增添助力!
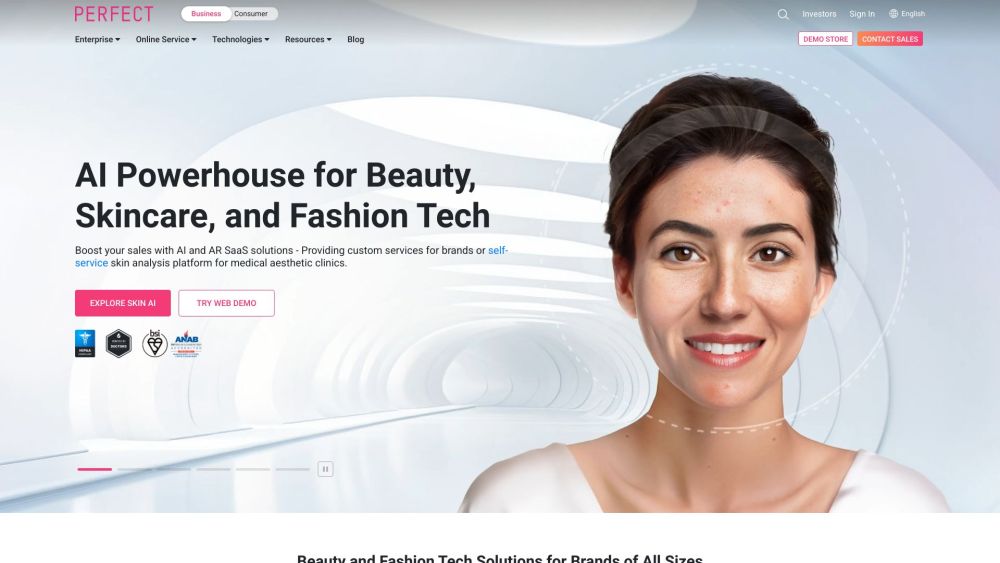
探索人工智慧與擴增實境解決方案在美容、時尚及護膚產業中的變革力量。隨著科技的不斷進步,這些創新工具正在重塑品牌與消費者的互動方式,提升他們的體驗,並個性化其產品。深入了解人工智慧與擴增實境如何徹底改變產品發現、虛擬試妝及量身訂製的推薦,為更具沉浸感及用戶友好的購物體驗鋪路。在競爭激烈的市場中保持領先,發掘人工智慧與擴增實境在品牌成長與成功中的潛力。
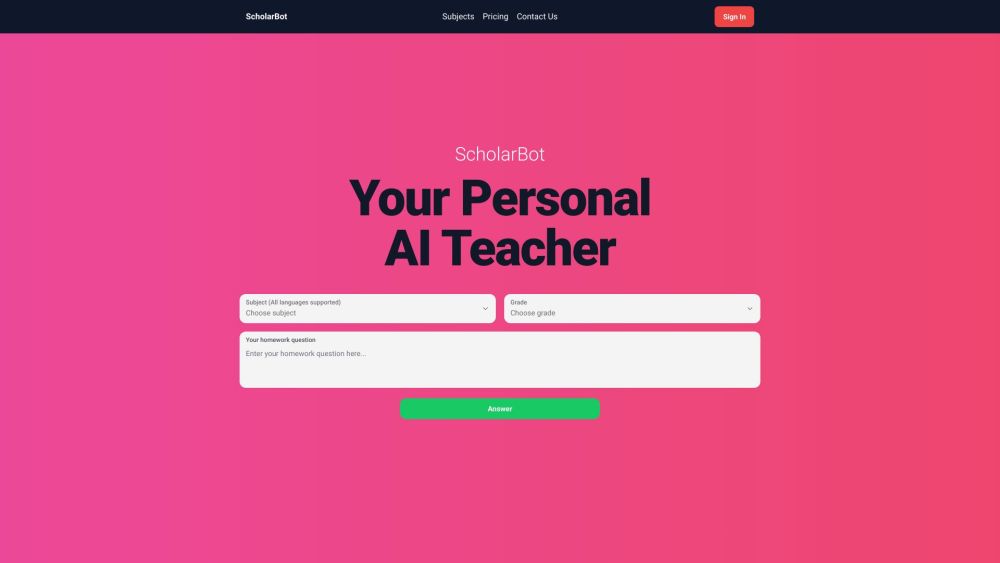
透過我們的 AI 驅動作業解決方案,開啟更聰明的學習旅程。這款創新的工具利用人工智慧轉變了學生與學習的互動方式,提供即時的幫助,增強理解能力。提升您的學術之旅,今天就發現更高效的作業處理方式,助您提升成績!

介紹 Segment Anything,一個創新的 AI 平台,專門用於高效和精確的數據分割與分析。這個尖端工具使用户能夠以前所未有的方式從數據中挖掘有價值的見解。
Find AI tools in YBX
