LLaVA++項目的重大突破:提升Phi-3和Llama-3模型的視覺能力
Most people like

發現一款旨在輕鬆提升和放大圖像的AI工具。利用尖端技術轉變您的照片,改善質量和細節,使您的視覺效果輕鬆脫穎而出。非常適合設計師、攝影師或任何希望輕鬆提升圖像的人士。
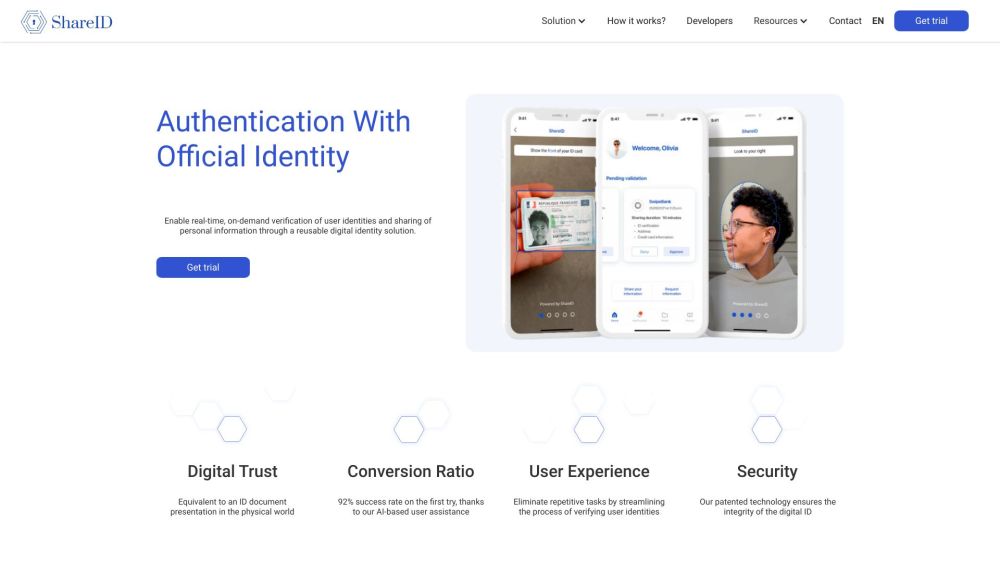
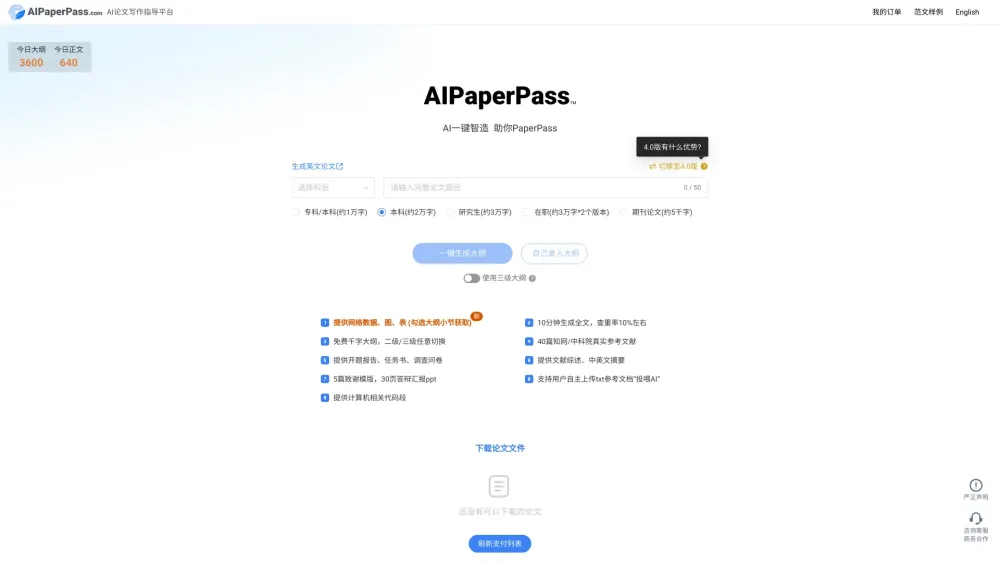
提升您的寫作技巧,享受AI增強的指導。探索人工智慧如何協助簡化您的寫作過程,提供個性化的反饋和建議,以改善清晰度、一致性和吸引力。無論您是撰寫論文的學生,還是準備報告的專業人士,我們的AI工具旨在在每一步支持您。立刻體驗未來的寫作輔助服務!
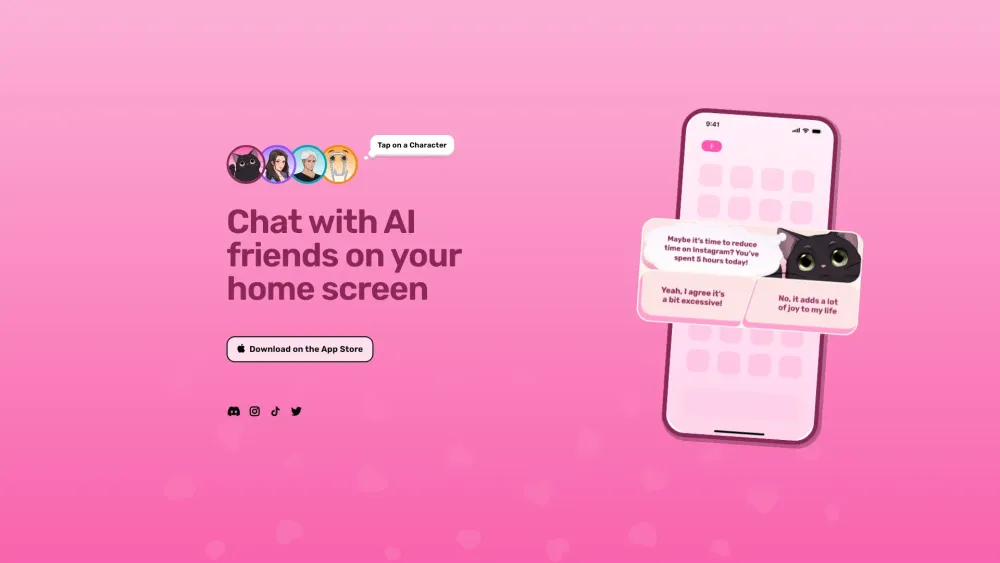
通過迷人的AI朋友和角色改變你的主畫面,為日常的數字互動增添個性和趣味。這些虛擬夥伴旨在讓你的設備更加生動和互動,提供娛樂和創意的觸感。探索如何增添這些獨特的元素可以提升你的主畫面,讓它不僅僅是功能性的展示,更能反映你的個人風格和興趣。
Find AI tools in YBX
Related Articles
Refresh Articles