Meta 推出創新人工智慧:多令牌預測模型現已可供研究使用
Most people like
摘要:SalesMind AI 是一款創新的工具,旨在優化 LinkedIn 潛在客戶開發,提升銷售績效與結果。憑藉其先進的人工智慧功能,SalesMind AI 簡化了尋找與接觸潛在客戶的過程,最終促進更佳的銷售成果。
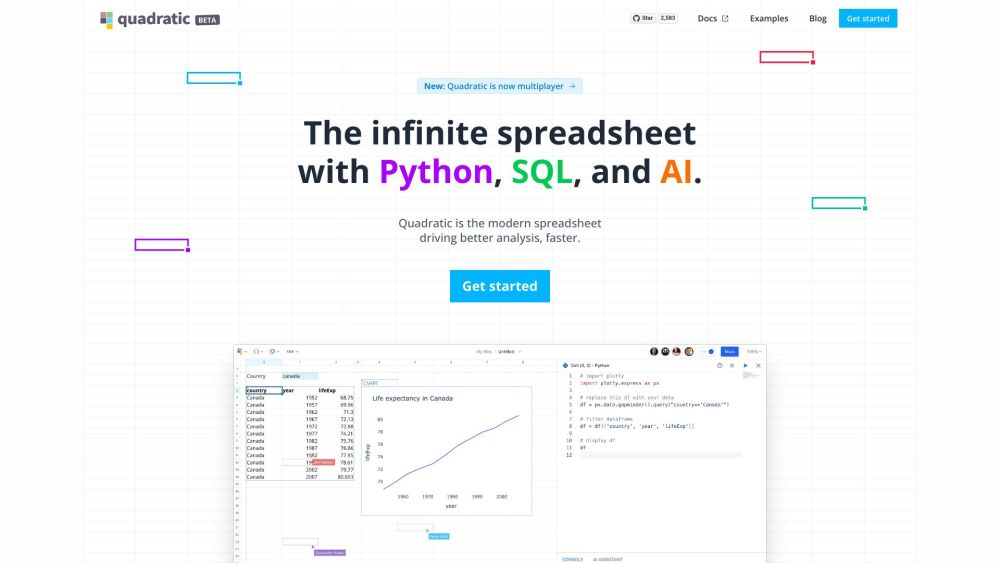
在當今快節奏的數位環境中,開發者需要高效的工具以簡化協作並提升生產力。即時電子表格提供了一個強大的解決方案,使團隊可以同時進行數據管理和分析。這種互動式的方式不僅促進了無縫的溝通,還能實現即時更新,成為開發者優化工作流程的必備資源。探索如何整合即時電子表格,提升您的專案管理和數據協作成效。
Find AI tools in YBX
Related Articles
Refresh Articles