Meta AI推出OpenEQA以提升人工智能代理的“具身智能”
Most people like

歌曲常常承載著深刻的訊息和情感,邀請聽眾探索其更深層的意義。詮釋歌曲背後的意義,不僅增強了我們對音樂的欣賞,也讓我們與藝術家的意圖及其表達的情感產生聯繫。在本指南中,我們將深入探討各種拆解歌詞和理解其內在故事的技巧。無論你是隨意的聽眾還是音樂愛好者,學習解讀歌曲意義都能豐富你的聆聽體驗,並促進與音樂藝術之間的更深連結。
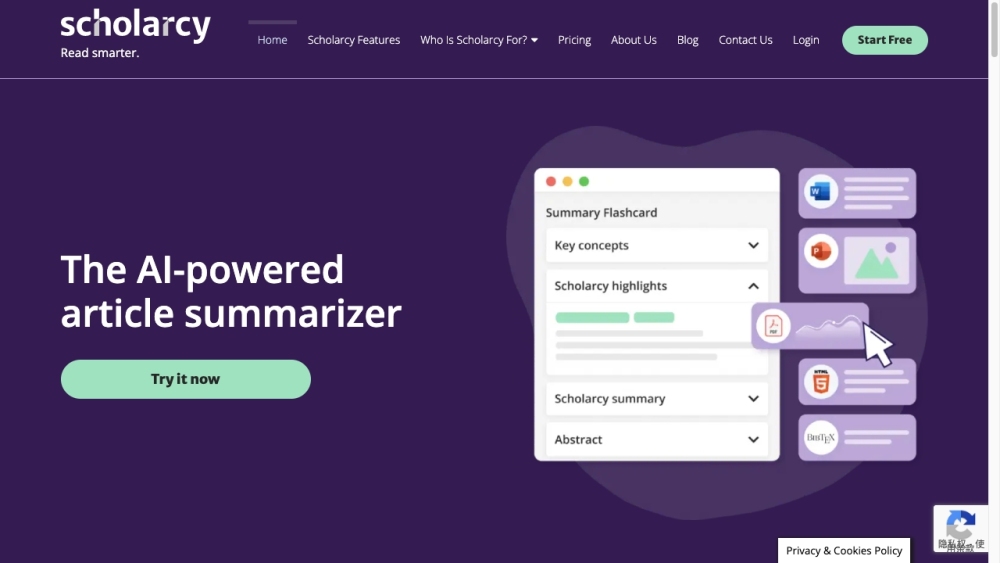
Scholarcy 是一款創新的 AI 工具,旨在將文章轉換為精簡的摘要卡片,使評估變得快速高效。透過 Scholarcy,釋放精簡學習的力量,讓您輕鬆掌握重要資訊,一目了然。
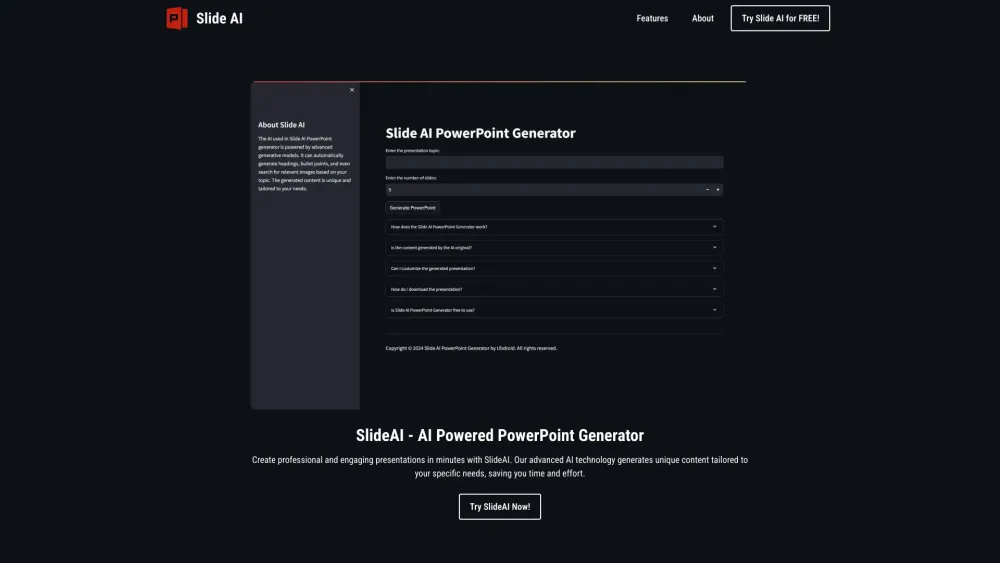
您是否時間緊迫卻需要呈現引人入勝的演示文稿?憑藉我們的創新工具,您可以在幾分鐘內製作出令人驚豔的演示。告別漫長的準備時間,迎接充滿活力的專業幻燈片,吸引觀眾的目光。探索如何輕鬆將您的想法轉化為視覺吸引力強的演示,而不妥協品質。
Find AI tools in YBX
Related Articles

Refresh Articles