NVIDIA 發布全新 8B AI 模型:高精度與高效率,支援 RTX 工作站
Most people like
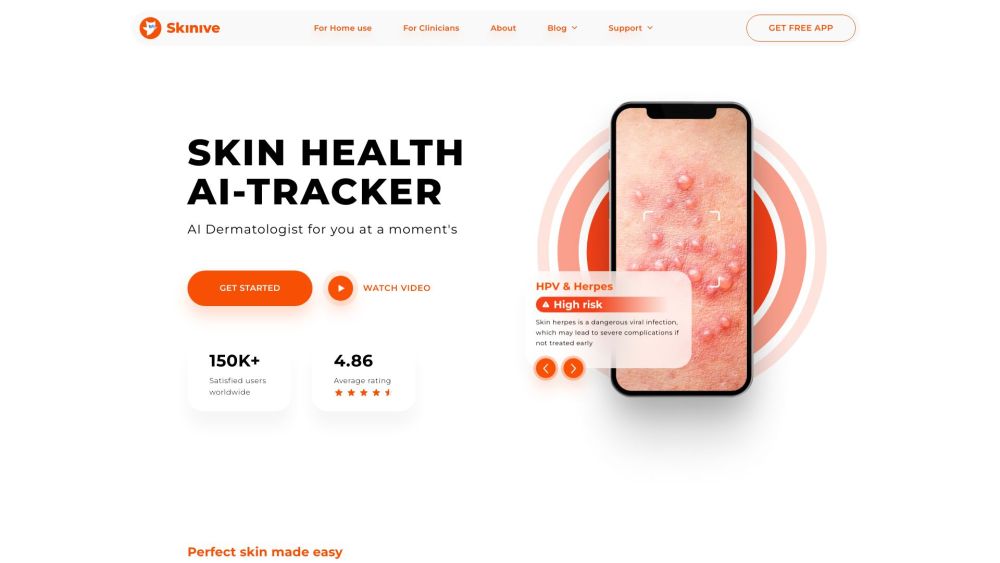

介紹一款創新的人工智能工具,旨在簡化您的學習過程,通過總結重要的學習材料並生成個性化的測驗。這款強大的工具幫助學生提高學習效率、記憶力和考試準備能力,使其成為任何追求學術成功者的寶貴資源。

Find AI tools in YBX
Related Articles
Refresh Articles