OpenAI GPT-4 面臨高達 44% 版權內容問題的指控
Most people like
解鎖人工智慧旅遊內容解決方案的力量,提升顧客體驗
探索人工智慧驅動的旅遊內容解決方案如何改變您的顧客體驗。透過運用智能演算法和個性化建議,這些創新工具能提升互動性並簡化旅遊規劃過程。深入了解未來的旅遊,利用旨在提升顧客旅程每一步的解決方案。
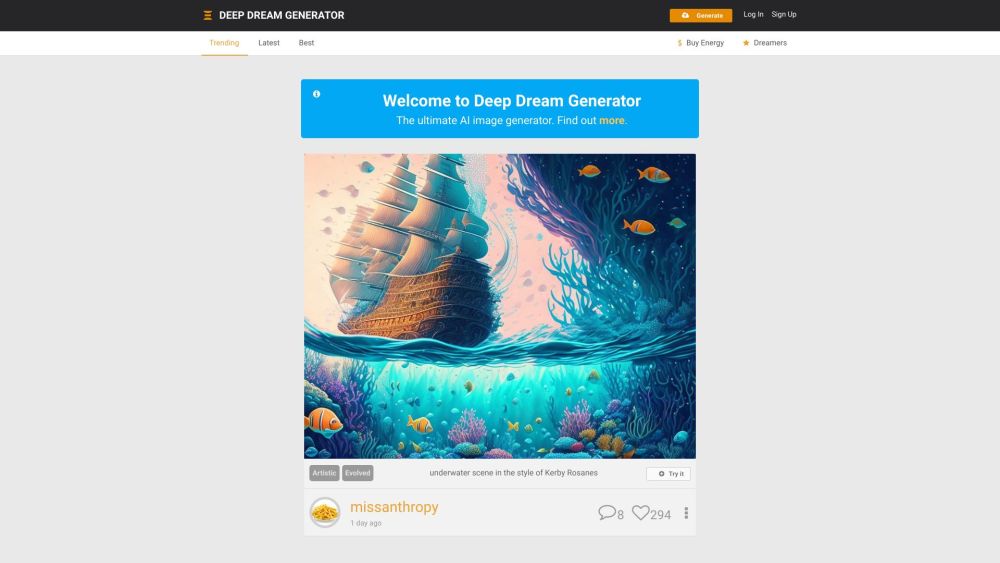
Deep Dream Generator是一款先進的人工智慧圖像生成器,運用先進的深度學習算法創造出獨特而具藝術感的視覺作品。探索這個迷人的人工智慧藝術世界,發現這個創新工具如何將平凡的圖像轉變為驚人的藝術傑作。
Find AI tools in YBX
Related Articles
Refresh Articles