微軟推出「MInference」示範,旨在革新人工智慧處理標準
Most people like
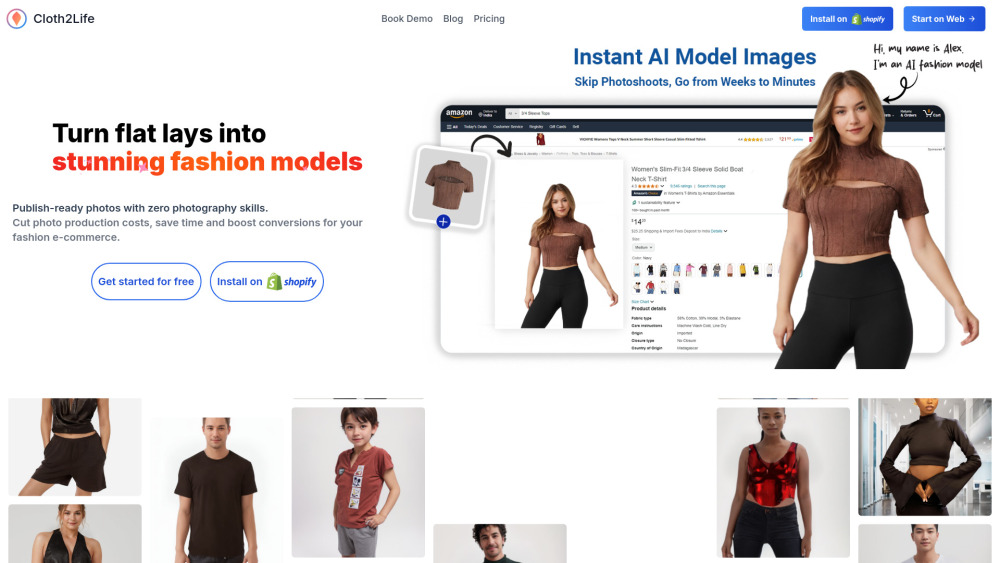
探索一個創新的AI平台,旨在直接從平面設計創造令人驚艷的時尚模特影像。這個開創性的工具利用人工智慧的力量讓您的時尚概念躍然紙上,使您能以動態且引人入勝的方式視覺化服裝。對於設計師和零售商而言,這個平台透過將靜態影像轉化為生動、引人注目的模特視覺,提升了您的行銷策略。
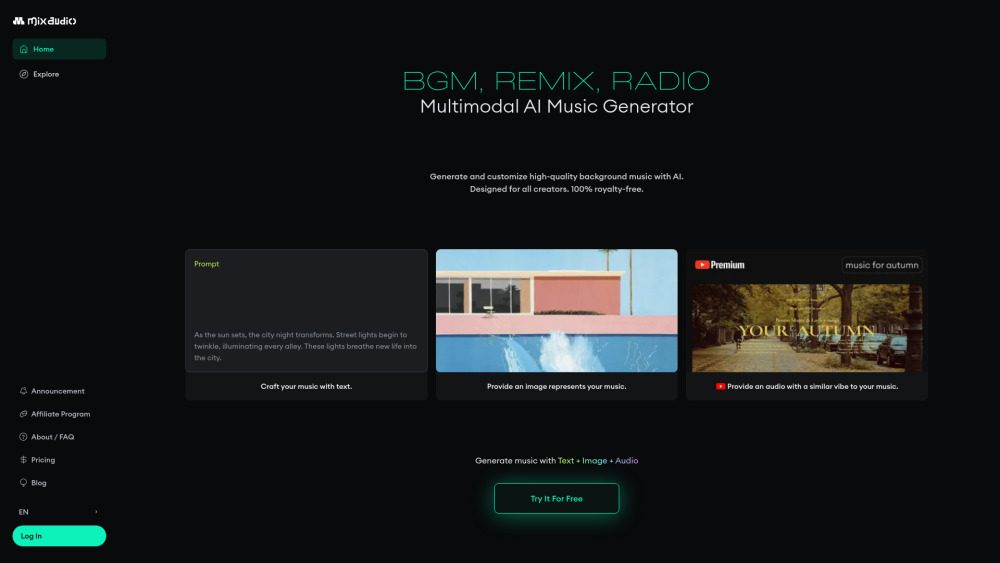
沉浸於令人振奮的音樂創作世界,體驗我們尖端的多模態人工智慧音樂生成器。在短短兩秒鐘內,您可以生成四條獨特的音軌,滿足從新手音樂家到資深專業人士的需求。釋放您的創造潛力,藉助量身定制的創新人工智慧驅動音樂,提升您的項目!
介紹 Stockimg AI:一個創新的 AI 驅動平台,旨在輕鬆打造令人驚艷的標誌、引人入勝的書籍封面和吸引眼球的海報。與 Stockimg AI 一起釋放你的創造潛力!
Find AI tools in YBX
Related Articles
Refresh Articles