研究人員釋放 ChatGPT 的潛力
Most people like
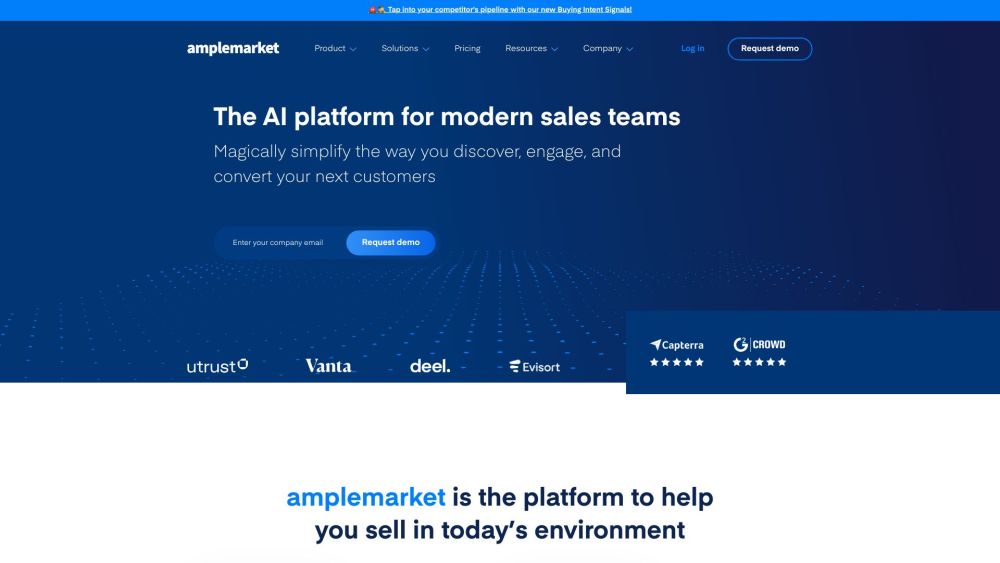
介紹專為當今銷售團隊量身打造的終極人工智慧平台。此創新解決方案旨在提升效率和提高生產力,利用人工智慧簡化流程,優化工作流程,並加強客戶互動。利用尖端科技轉變您的銷售策略,讓您的團隊能夠取得卓越的成果。

介紹一個沉浸於引人入勝互動故事的AI角色扮演平台。進入一個您可以塑造敘事、與生動角色互動並探索無限冒險的世界。無論您是資深角色扮演者還是新手,我們的平台都能提供充滿樂趣的體驗,激發您的創造力。加入我們,今天就來解鎖刺激的故事,展開難忘的旅程吧!

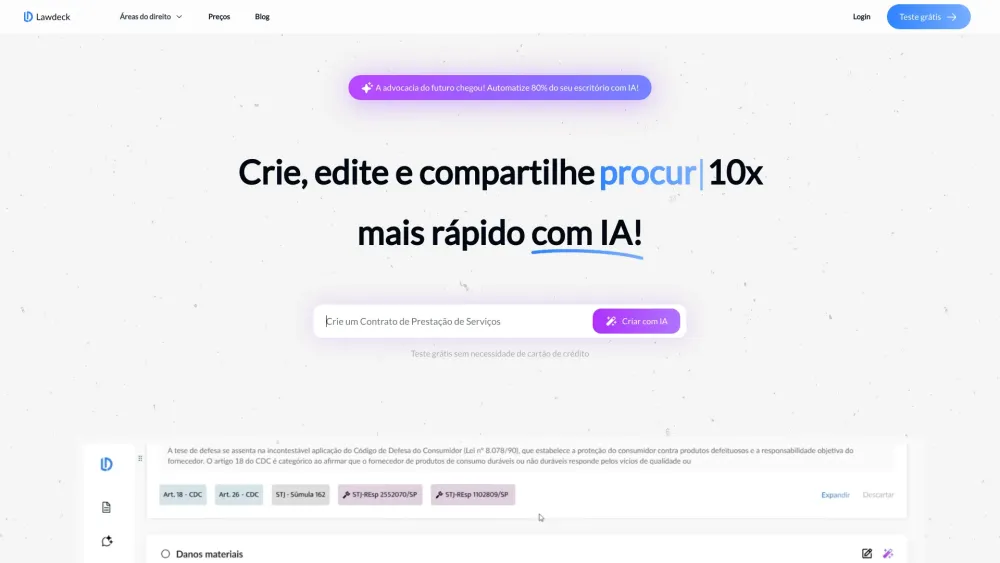
解鎖人工智慧驅動的法律文件創建與搜尋潛能。探索先進的人工智慧技術如何簡化草擬過程,並提升您迅速定位關鍵法律文件的能力。以高效的工具轉型您的法律實務,旨在簡化複雜任務並提高法律工作流程的準確性。今天就用最前沿的人工智慧解決方案優化您的法律業務。
Find AI tools in YBX
Related Articles
Refresh Articles