解鎖大型語言模型:駕馭在線實驗的混亂
Most people like
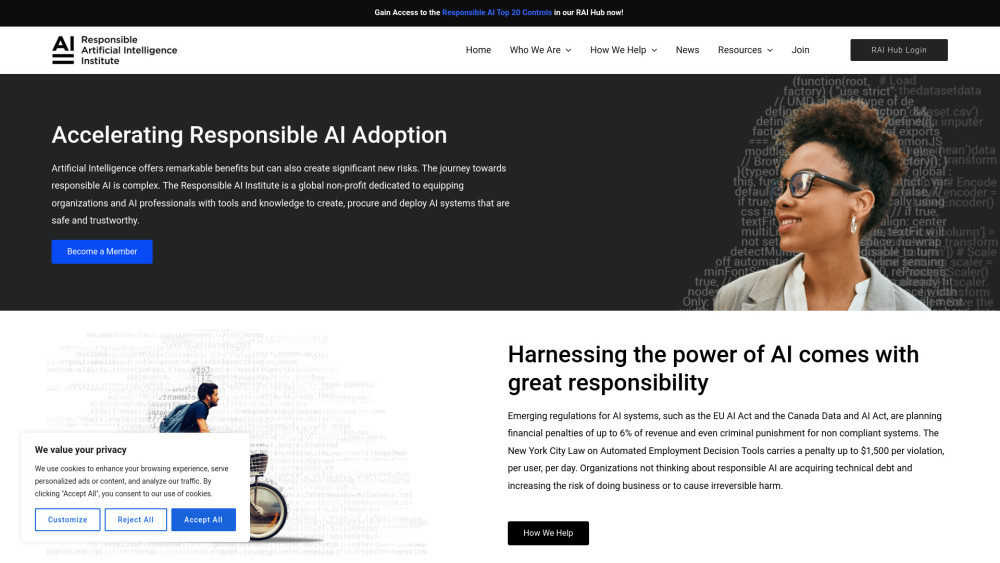
在人工智慧快速發展的時代,確保其安全與道德發展已成為當務之急。這個全球性非營利組織致力於推動倡議和指導方針,以促進Responsible AI Institute實踐。我們通過團結來自世界各地的專家、利益相關者與倡導者,旨在創造一個可持續的未來,使人工智慧惠及全人類。我們的使命強調在人工智慧技術中進行合作、透明與安全,為優先考慮社會福祉的創新解決方案奠定基礎。與我們共同塑造明天的負責任人工智慧環境。
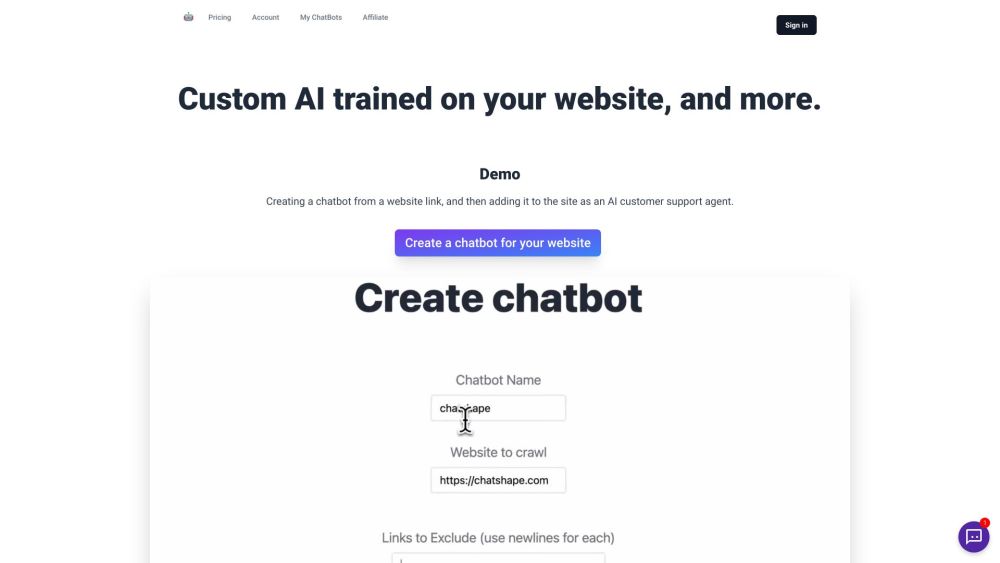
ChatShape 是一個創新的 AI 聊天機器人工具,旨在通過利用您網站的數據來提升客戶支持。憑藉其先進的訓練能力,ChatShape 使企業能夠提供更高效和個性化的協助,從而確保客戶獲得更佳的體驗。

發掘人工智慧音樂生成器的力量,讓您可以創建符合您需求的自訂音樂曲目。無論您是資深音樂家還是業餘愛好者,這款創新工具都能幫助您快速輕鬆地作曲,釋放您的創意潛能。深入探索AI生成音樂的世界,開始製作提升您專案和啟發觀眾的音樂作品。
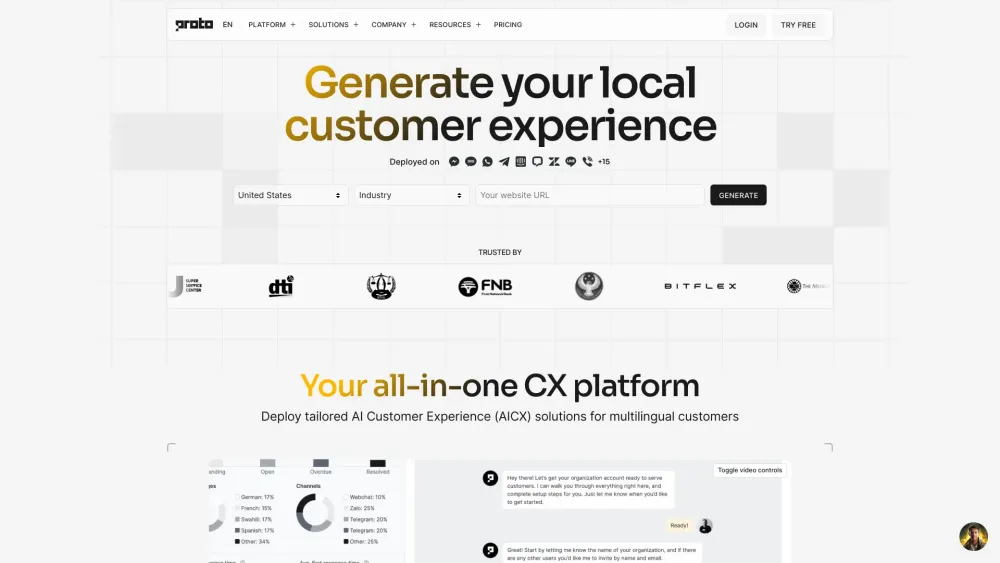
探索包容性客戶體驗(CX)自動化的力量,以及多語言聯絡中心自動化的好處。利用創新方案來提升互動、簡化溝通,並滿足多元化受眾的需求。通過擁抱優先考慮包容性和語言多樣性的技術,轉變您的客戶互動方式。
Find AI tools in YBX
Related Articles
Refresh Articles