谷歌发布PaliGemma:首款开放式多模态视觉-语言模型,提升AI能力
Most people like

以秒为单位对房地产图像进行匹配,快速提高视觉效果与市场吸引力。通过精确的图像搭配,我们能在短时间内提升房产展示的专业性和吸引力,从而吸引更多潜在买家的关注。合理运用图像对比和展示策略,能够有效提升客户的购买欲望,助力房地产行业的发展。
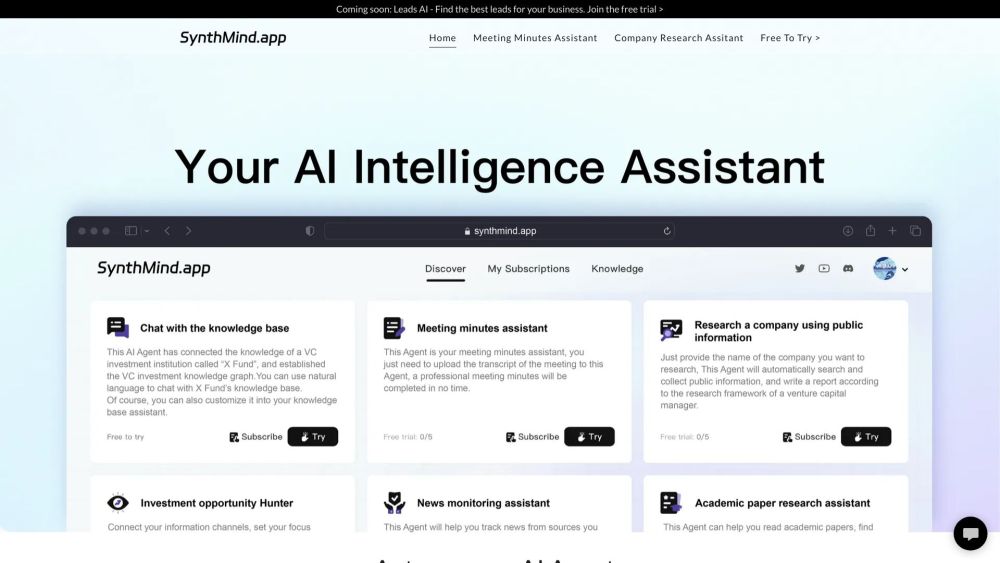
AI驱动的即时研究报告:提升洞察力的未来工具
探索如何利用人工智能技术生成即时研究报告,以实时提供深刻分析和关键见解。通过AI的强大能力,实现更高效的数据处理和决策支持,推动企业和组织的创新与发展。
Find AI tools in YBX
