AI Can Enable Smart Speakers to Detect the Direction of Your Voice
Most people like
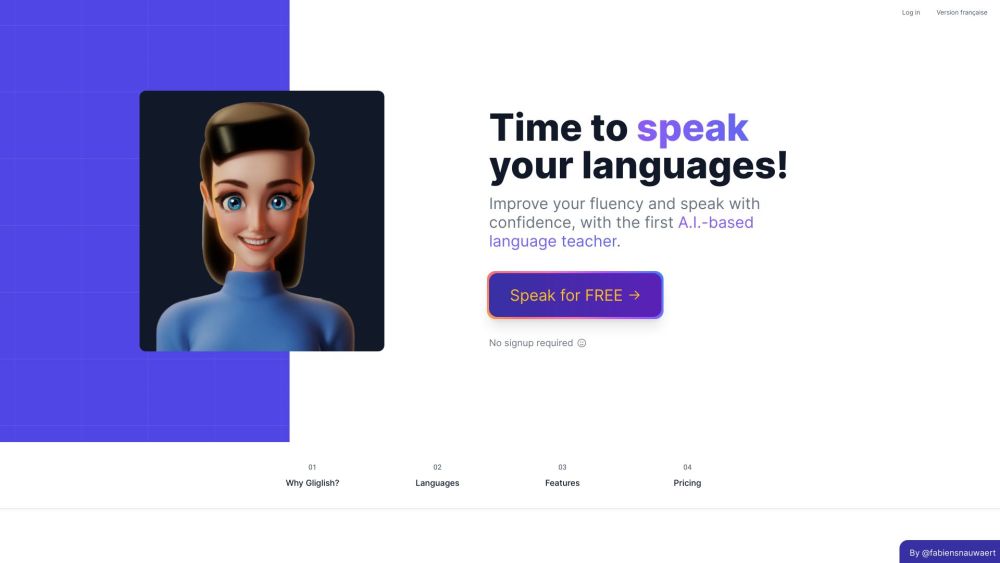
Gliglish is an innovative AI language teacher designed to boost your speaking and listening skills at an affordable price. Experience effective language learning with Gliglish and unlock your potential today!
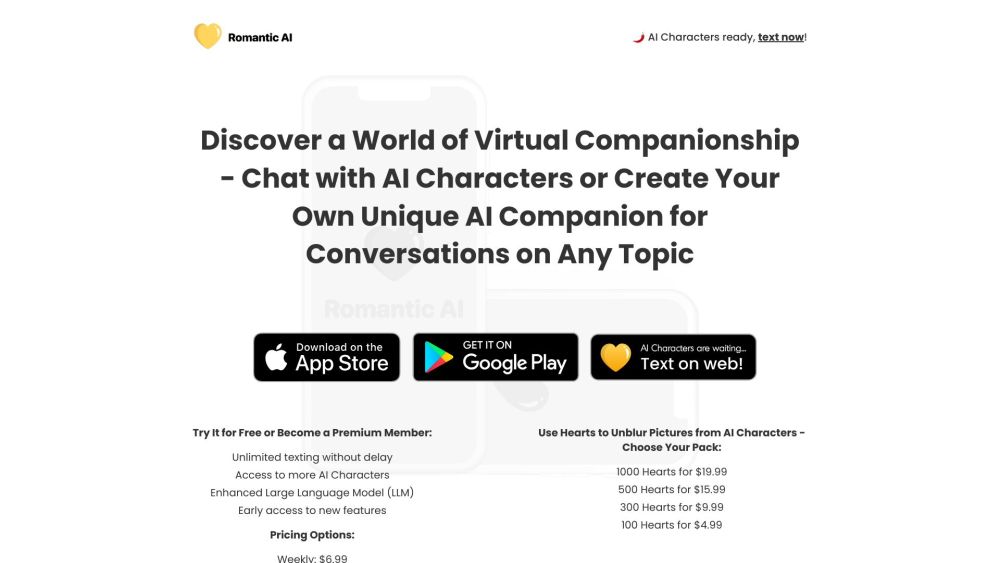
Discover the world of virtual companionship with your AI-powered girlfriend, where engaging conversations and meaningful connections await. Explore how technology enhances relationships, offering personalized interactions that enrich your experience.
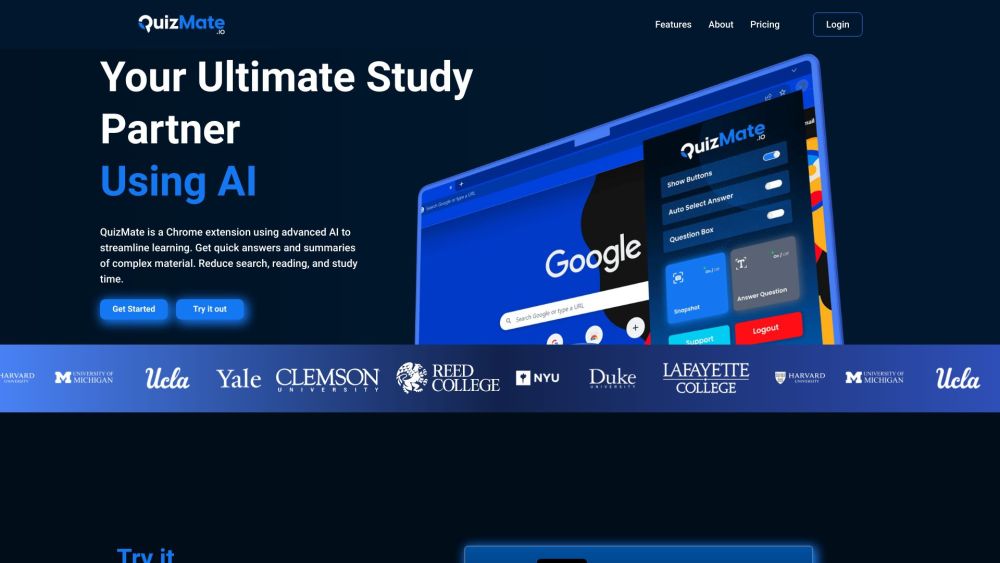
Enhance your learning experience with QuizMate, the AI-driven tool designed to streamline your study process.
Find AI tools in YBX
