Alibaba's Innovative AI System 'EMO' Generates Realistic Talking and Singing Videos from Your Photos
Most people like
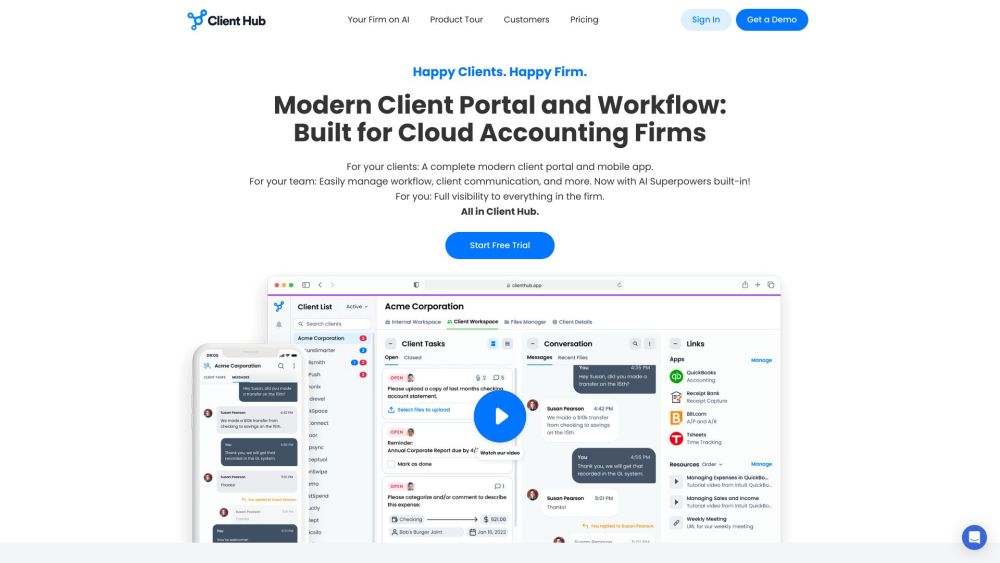
Streamline your accountant workflow with our all-in-one solution that includes a seamless client portal and additional powerful features. Maximize efficiency and enhance collaboration in your financial management processes.
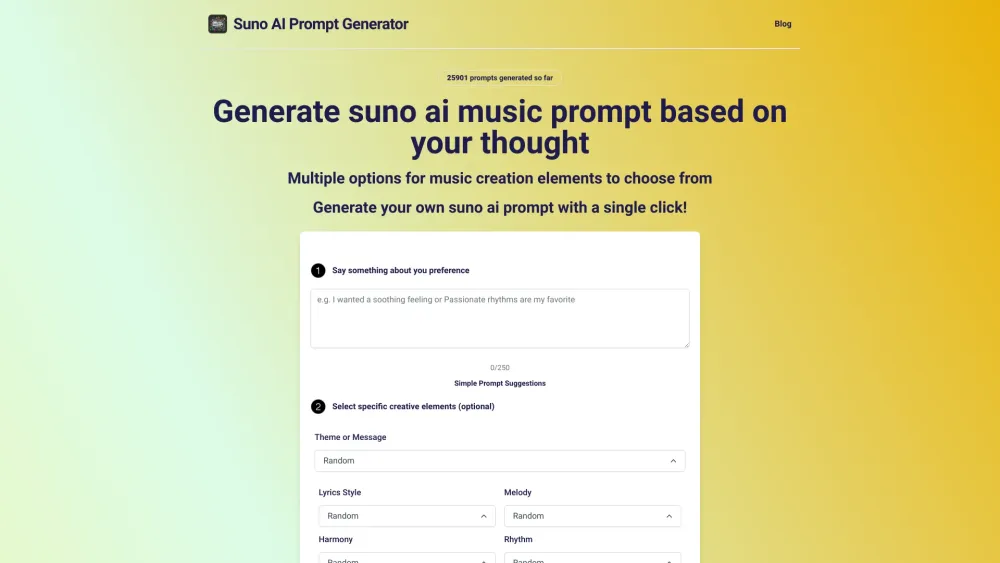
Are you looking to ignite your musical inspiration? Discover the power of transforming your ideas into captivating music prompts. By tapping into your thoughts, you can effortlessly create unique themes and melodies that resonate with you. Whether you’re an aspiring musician or a seasoned composer, this tool will help you channel your imagination into beautiful music. Start creating today!

Experience D&D 5e like never before with an AI Dungeon Master. Enjoy solo adventures or engage in multiplayer campaigns, all at your convenience—anytime, anywhere. Discover the limitless possibilities of tabletop gaming with the power of AI!
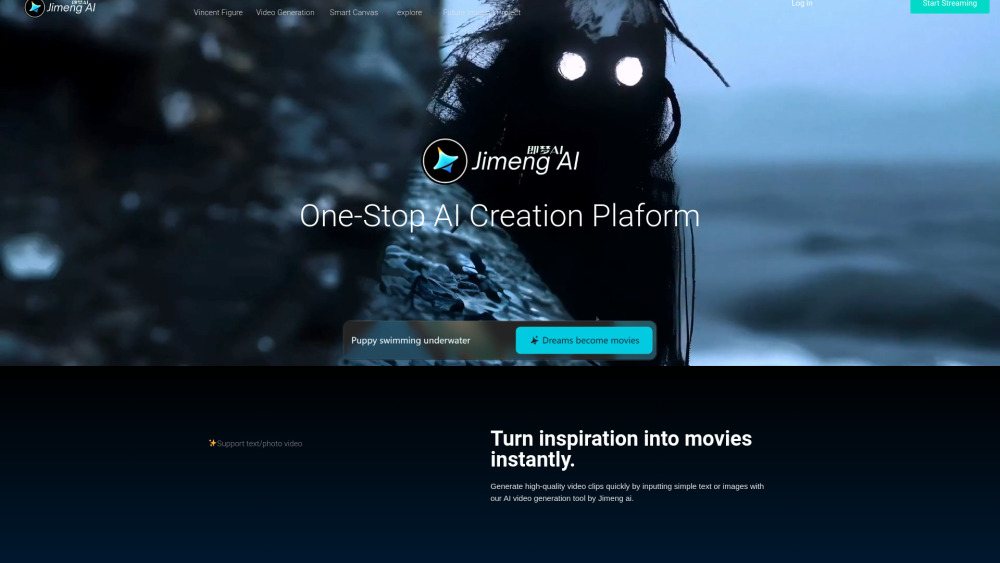
Introducing an innovative AI tool that transforms text and images into stunning videos in an instant. This cutting-edge technology streamlines the video creation process, enabling users to effortlessly bring their ideas to life. Whether for marketing, storytelling, or education, this tool is designed to enhance your content with ease and efficiency. Embrace the future of video production today!
Find AI tools in YBX
Related Articles
Refresh Articles