Can AI Chatbots Be Bound by a Legal Obligation to Tell the Truth? Exploring the Accountability of Artificial Intelligence in Communication.
Most people like

In an increasingly globalized world, effective communication across languages has become essential. Live speech translation for multilingual video calls enables seamless conversations, fostering collaboration and understanding among participants from diverse linguistic backgrounds. This innovative technology not only breaks down language barriers but also enhances the overall experience of online meetings and virtual events. With real-time translation capabilities, users can engage fully, share ideas, and connect effortlessly, making it a vital tool for businesses and individuals alike. Explore the benefits and features of this cutting-edge solution that is transforming the way we communicate in a multilingual landscape.
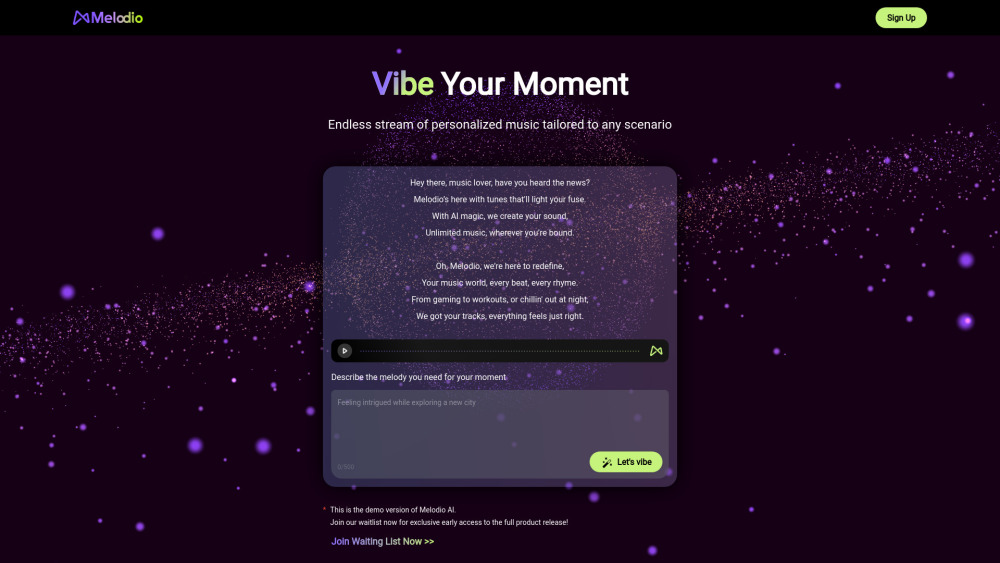
Discover the ultimate personalized AI music companion designed to enhance your listening experience. This innovative tool tailors music recommendations to your unique tastes, creating a custom soundtrack just for you. With advanced algorithms, it learns from your preferences and provides curated playlists that resonate with your mood, ensuring every note is perfectly suited to your vibe. Embrace the future of music with an AI companion that evolves alongside your musical journey, making every listening session uniquely yours.
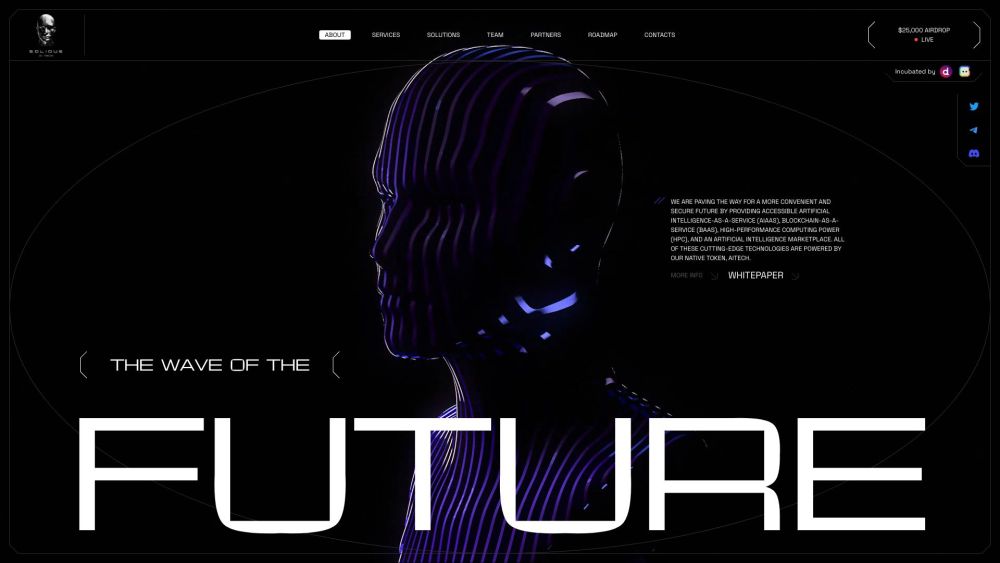
Solidus Ai Tech specializes in delivering user-friendly AI solutions and advanced blockchain technology, making cutting-edge innovations available to everyone.

Unlock the power of your very own AI writing assistant, designed to elevate your writing experience. Whether you're crafting engaging blog posts, compelling articles, or creative stories, this tool simplifies your writing process, enhances clarity, and boosts productivity. Say goodbye to writer's block and hello to seamless creativity with your personal AI ally, ready to assist you every step of the way.
Find AI tools in YBX
Related Articles
Refresh Articles