Meta Launches Its First Open AI Model Capable of Image Processing
Most people like
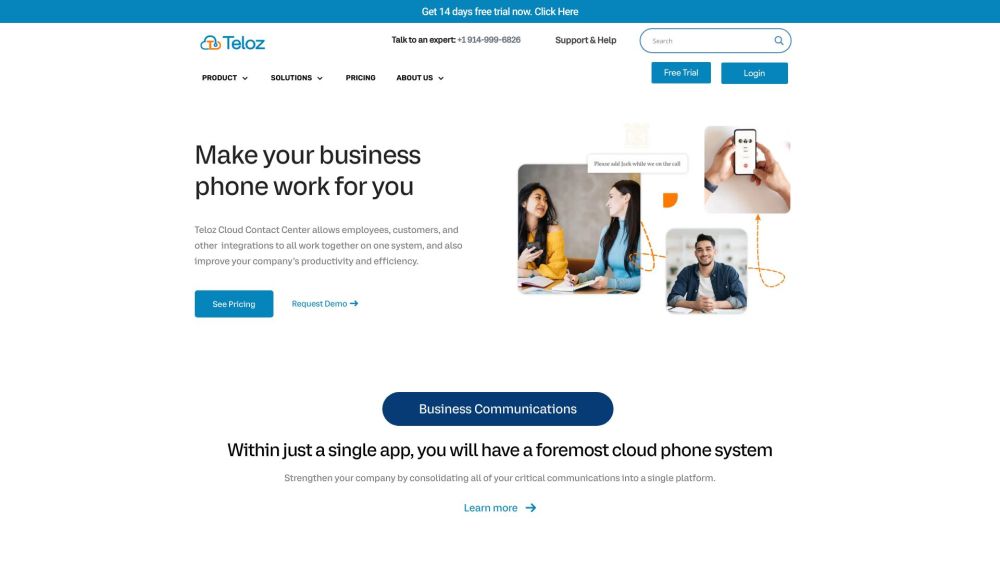
Teloz offers cutting-edge cloud-based communication solutions, equipped with advanced features for efficient contact center management.
Unlock the potential of AI-driven user insights to enhance your products like never before. By leveraging advanced analytics, businesses can fine-tune their offerings, ensuring they meet customer needs and preferences effectively. Discover how integrating AI insights can lead to more optimized, market-ready products that resonate with your audience.

Discover the world of unlimited AI-generated sounds, where creativity knows no bounds. Unlock a vast array of audio experiences tailored to inspire musicians, content creators, and sound designers alike. Whether you're seeking unique soundscapes for your projects or innovative sound effects for videos, our cutting-edge AI technology delivers endless possibilities. Dive in and explore the future of sound creation today!
Explore our innovative AI character chat platform, designed for engaging and safe interactions. Unlike other platforms, we prioritize a family-friendly environment, ensuring all discussions remain free from NSFW content. Join us for a unique experience where you can connect with characters in a protected space, perfect for users of all ages!
Find AI tools in YBX
Related Articles
Refresh Articles