Meta Launches Its First Open AI Model Capable of Image Processing
Most people like

Discover a powerful free translation tool that supports more than 100 languages, making communication easier for everyone, everywhere. Whether you’re traveling, studying, or connecting with friends worldwide, our tool ensures your messages break language barriers effortlessly.

Revolutionize your workflow with our AI platform designed specifically for web task automation through customizable templates. Simplify your processes and enhance productivity by leveraging intelligent automation tailored to your needs. Discover how our user-friendly templates can streamline repetitive tasks, allowing you to focus on what truly matters.

AI-powered collaborative diagramming platform for creating visual diagrams effortlessly.
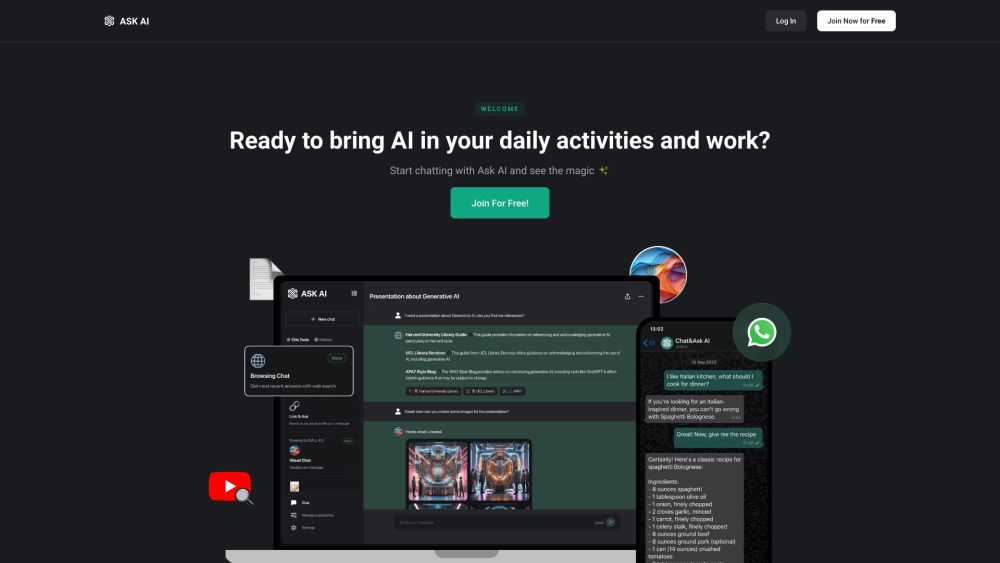
Discover an AI-powered chatbot assistant designed for instant answers and seamless writing support. Whether you need quick information or help enhancing your writing, our intelligent chatbot is here to assist you at any time. Experience the convenience of having a reliable virtual assistant that caters to your needs!
Find AI tools in YBX
Related Articles



Refresh Articles