OpenAI Explores Text Watermarking for ChatGPT to Identify Cheating Among Students
Most people like
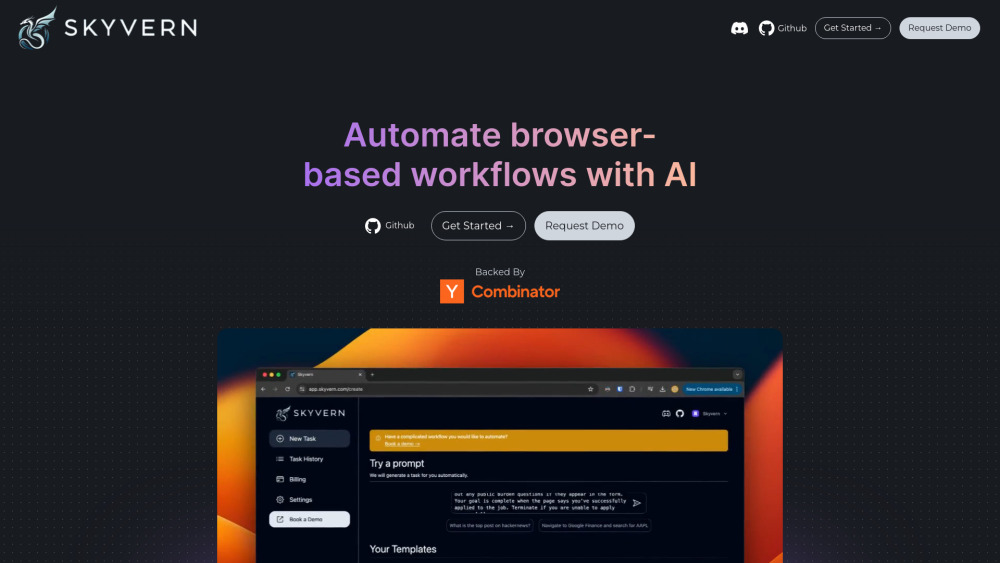
Introducing an Open Source AI Agent Designed for Automating Browser-Based Workflows
Unlock the potential of streamlined productivity with our Open Source AI Agent, tailored specifically for automating browser-based tasks. This innovative tool empowers users to enhance efficiency by effortlessly managing repetitive processes, making workflow automation accessible to everyone. Elevate your online tasks today!

Transform your ideas into captivating videos with our AI-powered tool that seamlessly converts text and images into high-quality visual content. Whether you're creating engaging marketing materials or stunning social media posts, our innovative solution streamlines the video production process, making it accessible to everyone. Discover how you can elevate your storytelling and captivate your audience effortlessly.

Discover the best ChatGPT alternatives for enhanced AI chat capabilities! Engage in dynamic conversations and elevate your communication experience with advanced chat solutions tailored to your needs. Whether you're seeking innovative features or superior performance, explore these powerful options for transformative interactions.
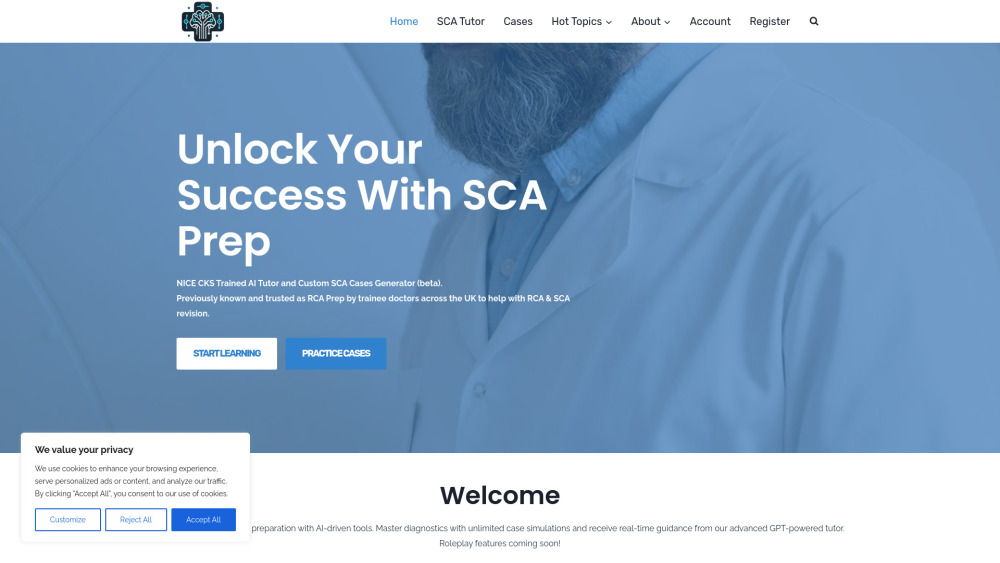
Unlock your potential and enhance your study strategies with the latest in AI technology. An AI tutor can offer personalized guidance, efficient study plans, and targeted practice questions, all tailored to your needs. Whether you’re preparing for medical certification exams or optimizing your understanding of complex subjects, integrating an AI tutor into your study routine can significantly boost your confidence and performance. Dive into a smarter, more effective way to prepare for your medical exams today!
Find AI tools in YBX
Related Articles
Refresh Articles