OpenAI: NY Times 'Manipulated' ChatGPT to File a Lawsuit Against Us
Most people like
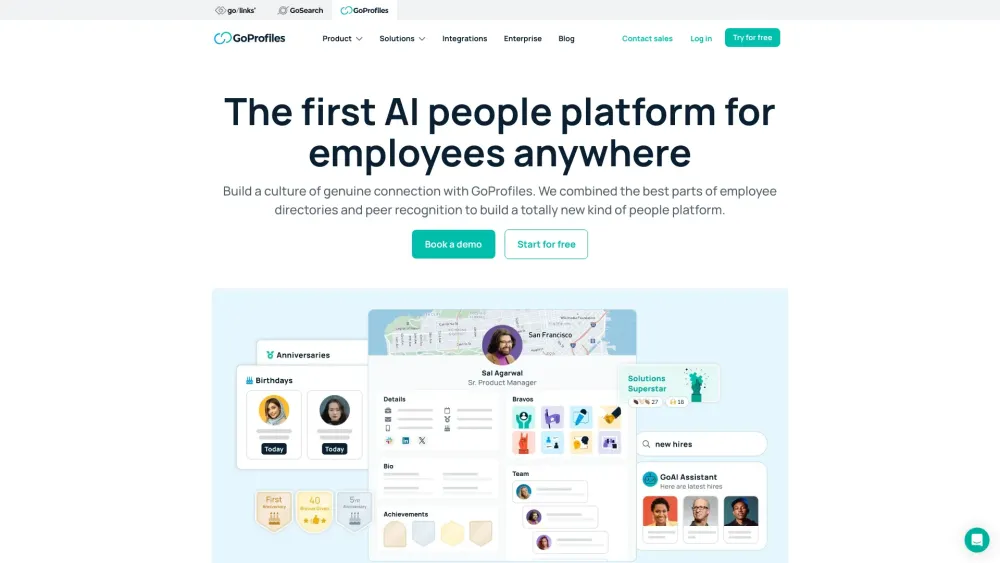
Introducing the AI-driven people platform designed for employees, no matter where they are located.
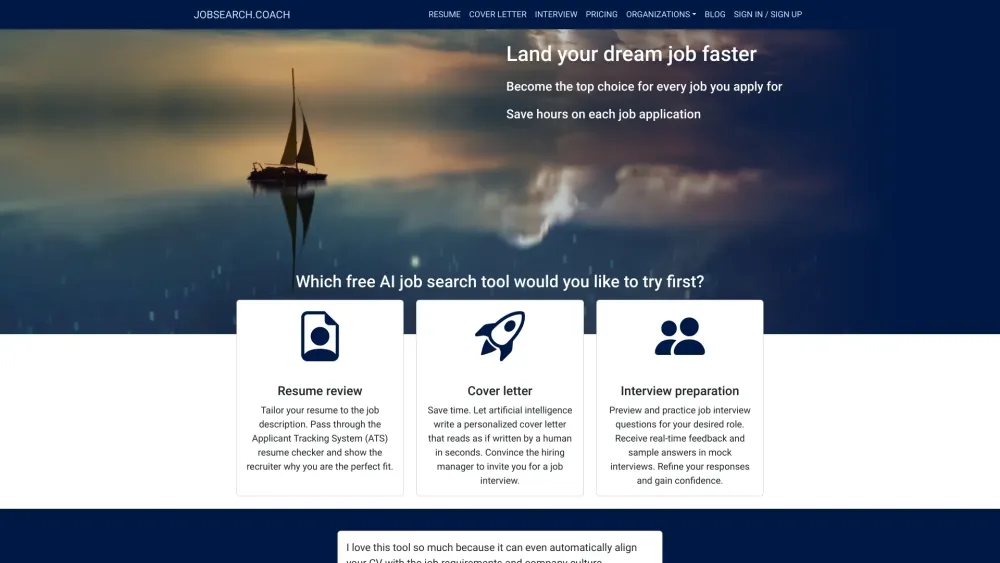
Enhance your resume and cover letter for maximum impact. Prepare for job interviews by practicing questions and receiving instant feedback.
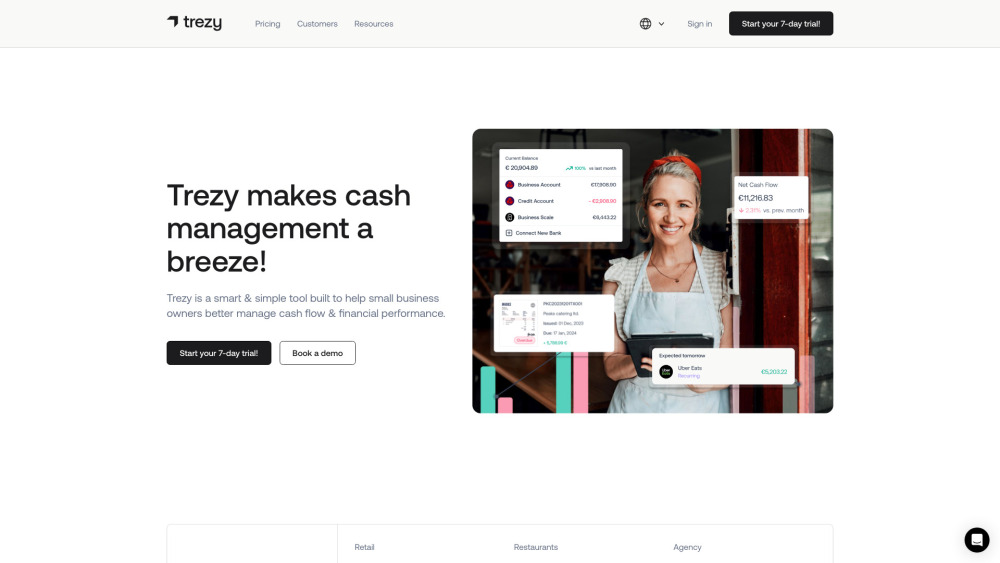
Effective Cash Flow Management Tools for Small Businesses
In today's fast-paced economy, small businesses face unique financial challenges. Ensuring a steady cash flow is crucial for maintaining operations, meeting obligations, and fostering growth. This article delves into the top cash flow management tools tailored for small businesses, designed to streamline financial processes and enhance decision-making. Whether you’re looking to track expenses, forecast revenue, or improve your overall financial health, these tools can empower you to take charge of your cash flow and drive your business towards success.
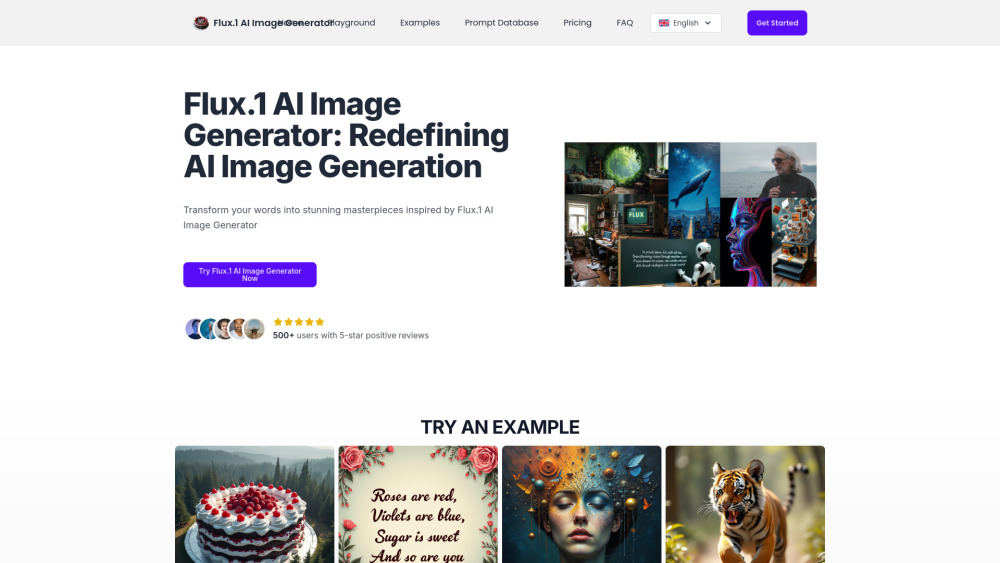
Discover the power of AI image generators that transform text prompts into stunning visuals. With cutting-edge technology, these tools allow users to convert imaginative descriptions into captivating images, bridging creativity and innovation effortlessly. Unlock your artistic potential and explore the limitless possibilities of AI-driven imagery!
Find AI tools in YBX
Related Articles
Refresh Articles