Reddit CEO Insists Microsoft Must Pay to Access Search Data on the Platform
Most people like

Explore and create captivating AI-generated music effortlessly. Unleash your creativity with innovative tools designed for music enthusiasts and producers alike, enabling you to discover unique sounds that transform your musical experience. Dive into the world of artificial intelligence and elevate your compositions today!

In today's rapidly evolving digital landscape, conversational AI stands at the forefront of technological innovation. This branch of artificial intelligence focuses on creating systems that can engage in human-like dialogue, enhancing user experiences across platforms. From chatbots to virtual assistants, the development and analysis of conversational AI play a crucial role in transforming how we interact with technology. Join us as we delve into the latest advancements and insights in this exciting field, uncovering the potential that conversational AI holds for businesses and users alike.

Transform your real estate business with our AI platform designed specifically for agents. Experience personalized content creation and virtual room remodeling that streamlines your workflow. Save valuable time and boost your sales—close more deals effortlessly!
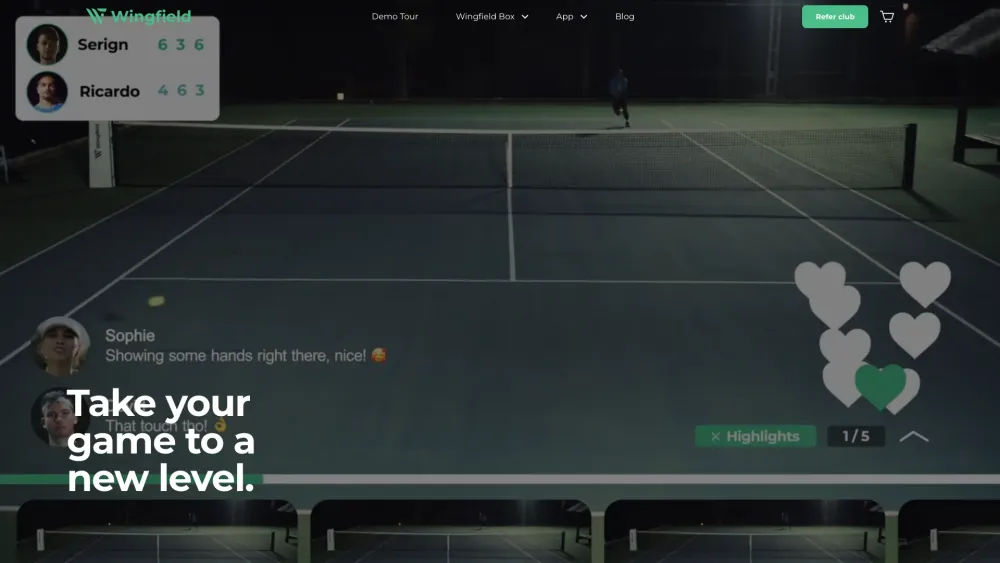
Are you ready to elevate your tennis game from the comfort of your home? Our innovative virtual tennis experience combines cutting-edge technology with realistic gameplay, allowing you to immerse yourself in the sport you love. Whether you're a beginner looking to learn the basics or an advanced player honing your skills, this interactive platform offers tailored training sessions, competitive matches, and engaging challenges designed for all levels. Join a vibrant community of tennis enthusiasts and transform your game today!
Find AI tools in YBX
Related Articles
Refresh Articles