Stability AI Unveils Research Preview of Stable Video Diffusion Models for Creative Applications
Most people like
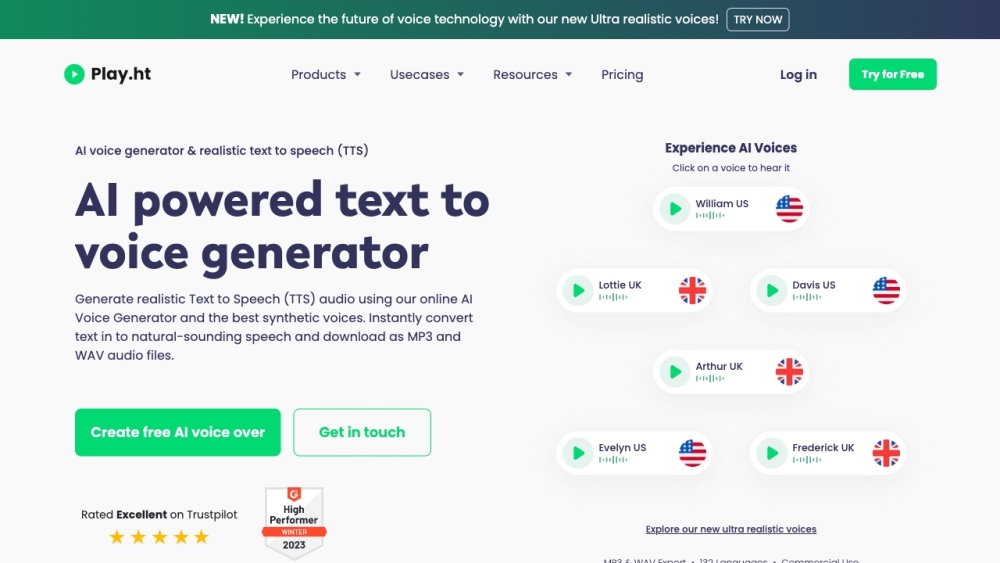
Discover PlayHT, an innovative AI Voice Generator platform that offers an impressive selection of over 600 voices in numerous languages. Explore the possibilities of transforming text into lifelike speech effortlessly.
In recent years, AI music creation platforms have revolutionized the way we compose, produce, and experience music. These innovative tools leverage advanced algorithms to assist musicians and creators in generating unique sounds and melodies. Whether you are a seasoned musician or an aspiring artist, AI music creation platforms offer an exciting avenue for artistic exploration and creativity. Discover how these cutting-edge technologies are reshaping the music industry and empowering creators worldwide.

In today's digital landscape, crafting engaging content that resonates with readers is more important than ever. Humanizing AI-generated content not only enhances readability but also fosters a genuine connection with the audience. By incorporating relatable language and a conversational tone, we can transform technical information into accessible narratives. This approach not only captures attention but also encourages deeper understanding, making your content stand out in a sea of information. Embrace the art of humanizing AI content to elevate your writing and engage your readers effectively.
Introducing an innovative AI tool designed to automate the creation and posting of short videos effortlessly. This powerful software streamlines the entire process, allowing users to produce engaging video content quickly and efficiently. With its user-friendly interface, it transforms your ideas into captivating videos in no time, making it an essential resource for content creators and marketers alike. Enhance your online presence and boost your engagement with this cutting-edge solution for short video automation.
Find AI tools in YBX
Related Articles
Refresh Articles