"Testing the Reliability of Multimodal AI Deployments with MMCBench"
Most people like
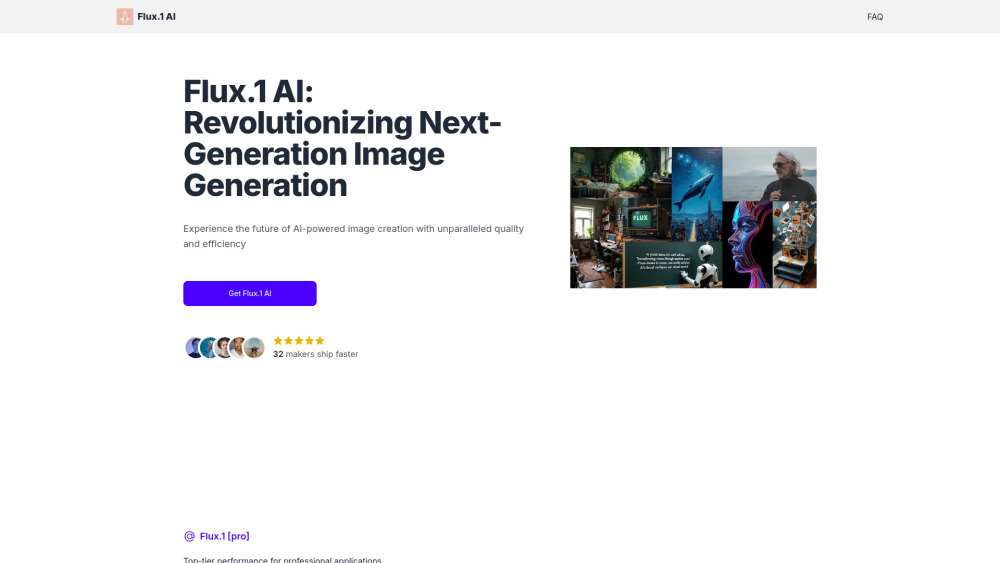
Explore the cutting-edge world of advanced AI technologies designed to generate stunning images from text. This innovative approach leverages powerful algorithms and deep learning techniques to transform written descriptions into vivid visual representations. Whether you're an artist, designer, or simply curious about the potential of AI, this comprehensive guide will illuminate the capabilities and applications of text-to-image generation, showcasing how it is revolutionizing creativity and content production.
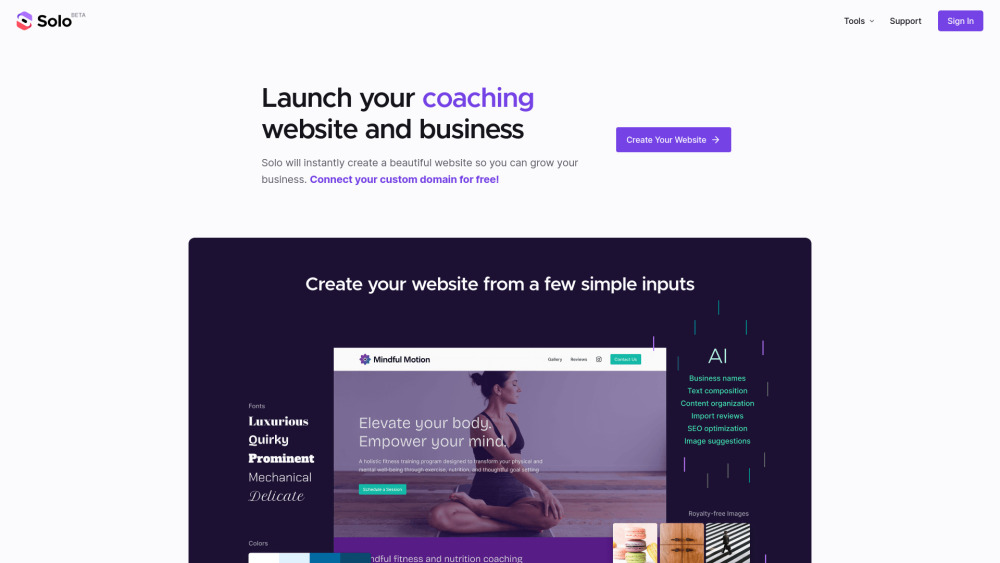
In today's digital landscape, having an impactful online presence is crucial for businesses of all sizes. An AI website creator simplifies the process of building a professional website, allowing entrepreneurs and companies to create stunning sites effortlessly. By leveraging advanced technology, these tools provide customizable templates and user-friendly interfaces, empowering users to establish their brand identity and enhance customer engagement. Discover how an AI website creator can transform your business strategy and drive online success.
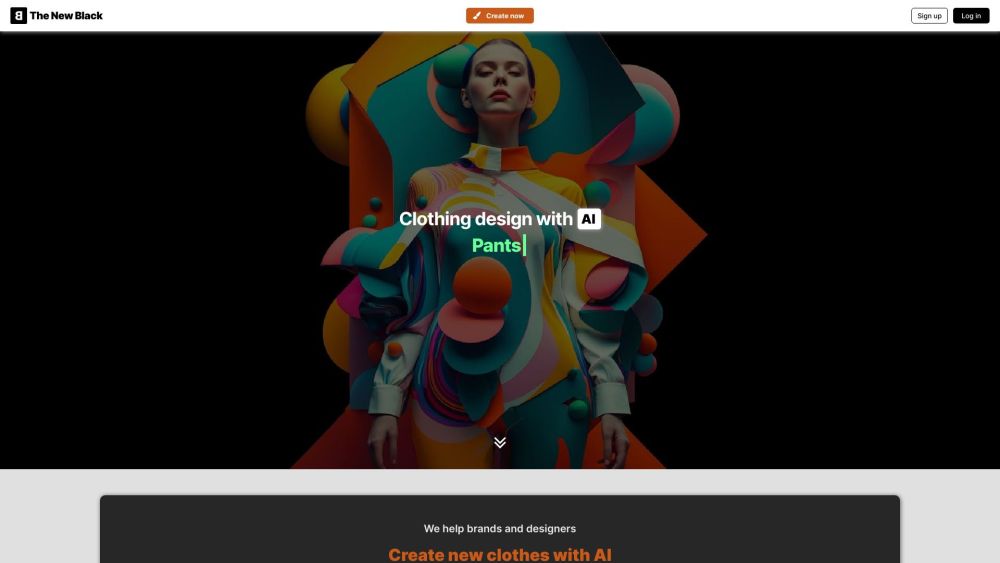
The New Black is an innovative website that harnesses the power of AI to create unique clothing designs, empowering designers to elevate their creativity and streamline their design processes.

Elevate your research game with ALANI, your AI-powered assistant designed to supercharge the way you gather and analyze information.
Find AI tools in YBX
