Chinas DeepSeek Coder: Das erste Open-Source-Coding-Modell, das GPT-4 Turbo übertrifft.
Most people like
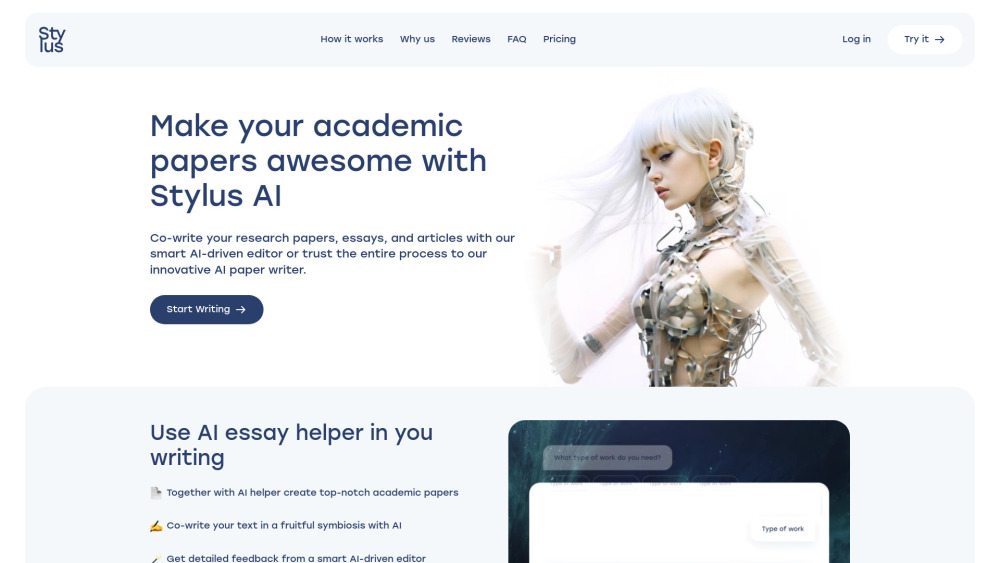
Präsentation unserer KI-Plattform, die speziell für das Schreiben, Bearbeiten und Forschen entwickelt wurde. Dieses innovative Tool nutzt die Leistungsfähigkeit der künstlichen Intelligenz, um Ihr Schreiberlebnis zu verbessern, den Bearbeitungsprozess zu optimieren und umfassende Recherchen zu unterstützen. Ob Sie Student, Fachkraft oder kreativer Denker sind, unsere KI-Plattform steht bereit, um Ihre Inhalte zu optimieren. Entdecken Sie, wie unsere Technologie Ihre Schreibprojekte mit Präzision und Effizienz transformieren kann.
Führen Sie dynamische Gespräche mit verschiedenen Open-Source-Sprachmodellen (LLMs) für ein bereicherndes Erlebnis. Entdecken Sie die Kraft dieser fortschrittlichen Tools, während Sie ihre einzigartigen Fähigkeiten und Anwendungen erkunden. Ob Sie Ihre Projekte verbessern oder einfach nur Neugier über KI stillen möchten, die Verbindung zu mehreren LLMs eröffnet Ihnen eine Welt voller Möglichkeiten.

Wonsulting unterstützt nicht-traditionelle Arbeitssuchende dabei, ihre Traumberufe durch personalisiertes Coaching und wertvolle Ressourcen zu erreichen.
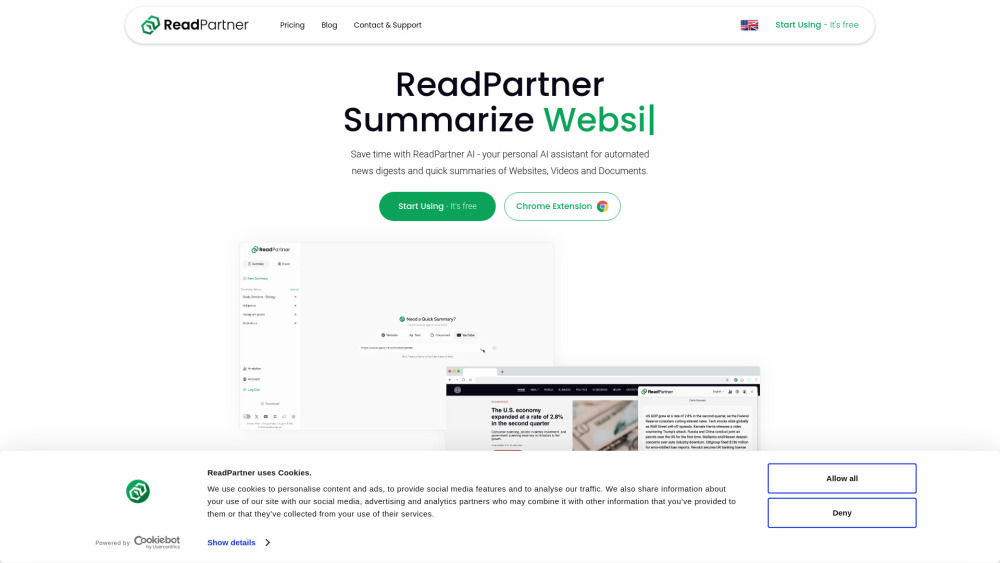
Entdecken Sie die Leistung unseres KI-News-Digest- und Zusammenfassungstools, das entwickelt wurde, um Sie mühelos mit den neuesten Nachrichten auf dem Laufenden zu halten. Dieses innovative Tool nutzt die Möglichkeiten der künstlichen Intelligenz, um Nachrichtenartikel auszuwählen und zusammenzufassen, und bietet Ihnen prägnante sowie relevante Informationen, die auf Ihre Interessen abgestimmt sind. Bleiben Sie informiert, ohne überwältigt zu werden, und verbessern Sie Ihr Leseerlebnis mit maßgeschneiderten Einblicken aus der Welt der Nachrichten.
Find AI tools in YBX
Related Articles
Refresh Articles