Eingeschränkter Zugang zu LLMs? Snowflake stellt länderübergreifende Inferenz für verbesserte Verfügbarkeit vor.
Most people like

Entdecken Sie die Kraft unserer KI-gesteuerten Plattform, die speziell für Fachkräfte im Bereich der psychischen Gesundheit entwickelt wurde. Maßgeschneidert zur Verbesserung therapeutischer Praktiken, optimiert dieses innovative Werkzeug das Kundenmanagement, bietet aufschlussreiche Analysen und fördert eine effektive Kommunikation, wodurch die Unterstützung des psychischen Wohlbefindens neu definiert wird. Schließen Sie sich der Bewegung an, die die psychische Gesundheitsversorgung mit modernster Technologie transformiert, die Fachleuten die Möglichkeit gibt, optimale Ergebnisse für ihre Klienten zu erzielen.

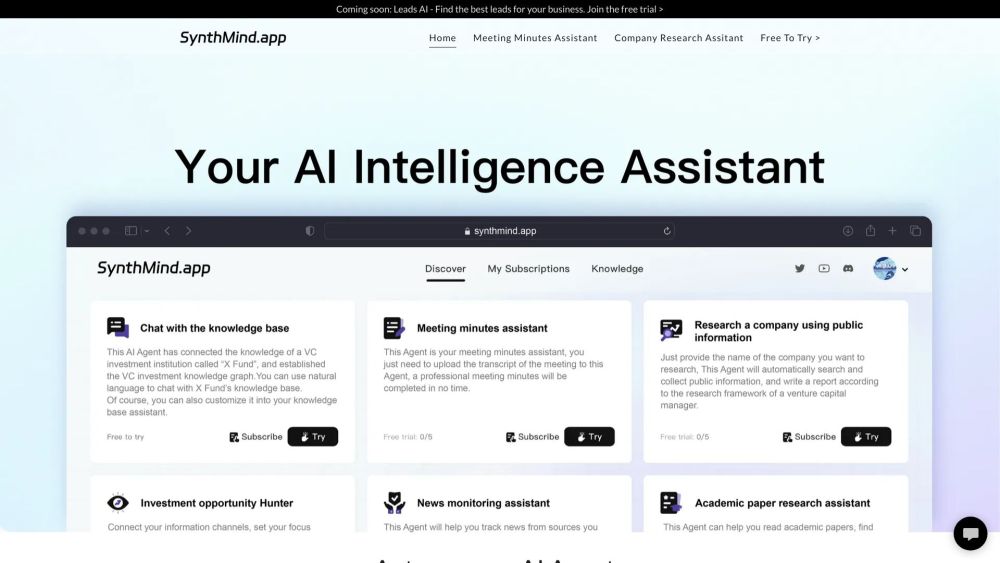
In der heutigen, schnelllebigen Welt ist der Zugang zu zeitnahen und präzisen Informationen entscheidend für fundierte Entscheidungen. Unsere von KI unterstützten Sofortforschungsberichte bieten umfassende Einblicke in Rekordzeit und ermöglichen es Unternehmen und Einzelpersonen, der Konkurrenz einen Schritt voraus zu sein. Durch die Nutzung der Möglichkeiten künstlicher Intelligenz liefern wir maßgeschneiderte Forschung, die Ihr Verständnis komplexer Themen vertieft und es Ihnen ermöglicht, mühelos informierte Entscheidungen zu treffen. Tauchen Sie ein in eine Welt der schnellen Forschung und erleben Sie die Zukunft der Informationsbeschaffung noch heute!
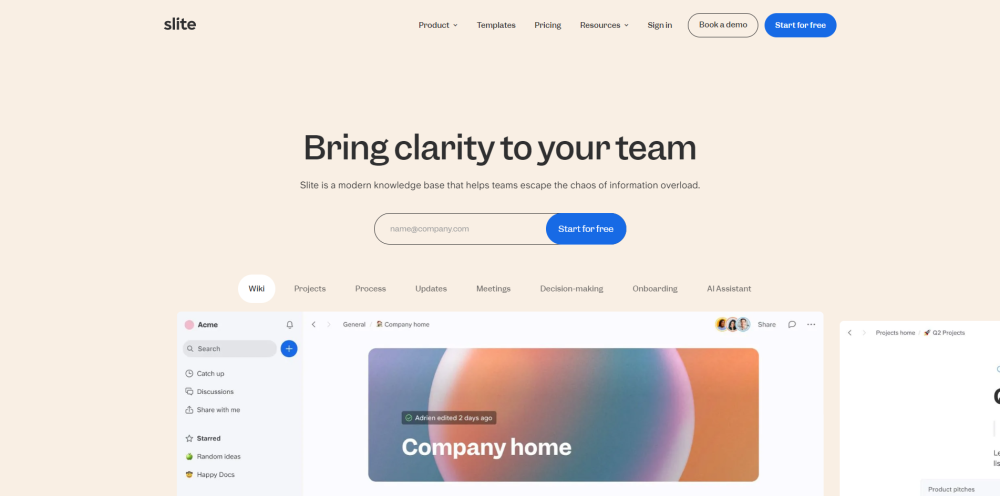
Entdecken Sie Slite, eine KI-gestützte Wissensdatenbank, die Ihnen einen nahtlosen Zugang zu zuverlässigen Unternehmensinformationen direkt zur Verfügung stellt.
Find AI tools in YBX
Related Articles
Refresh Articles