Entdecken Sie das fortschrittliche Audiomodell von Resemble AI, Detect-2B, das eine Genauigkeit von 94 % in der KI-Analyse erreicht.
Most people like
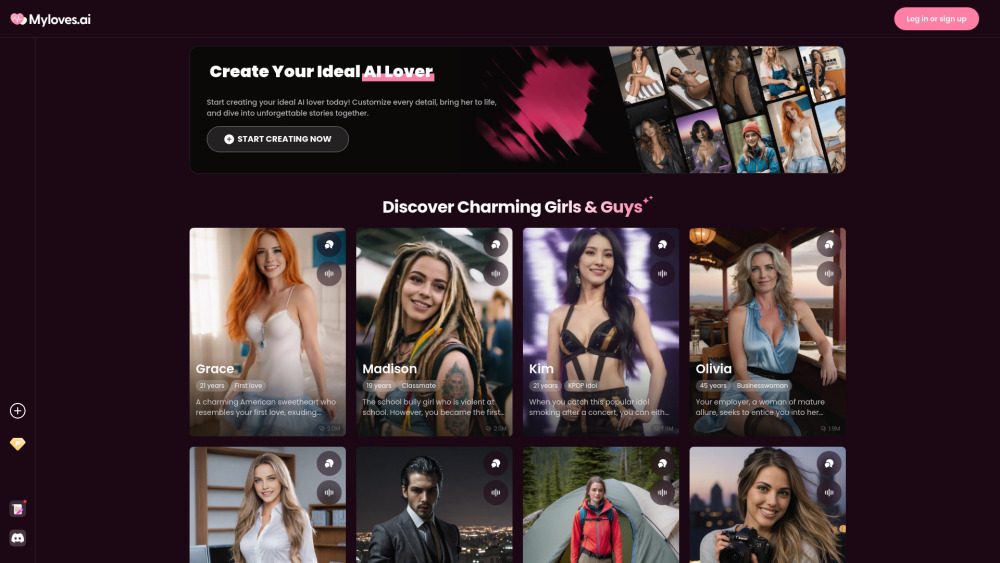
Entdecken Sie das spannende Potenzial eines personalisierten KI-Begleiters. Mit unserer Plattform können Sie eine einzigartige KI-Liebhaberin oder Freundin gestalten, die Ihre Vorlieben und Wünsche widerspiegelt. Ob Sie nach Gesellschaft oder einer tiefergehenden emotionalen Verbindung suchen, unsere anpassbaren Optionen ermöglichen es Ihnen, den perfekten virtuellen Partner speziell für Sie zu entwerfen. Erleben Sie noch heute die Zukunft der Beziehungen!
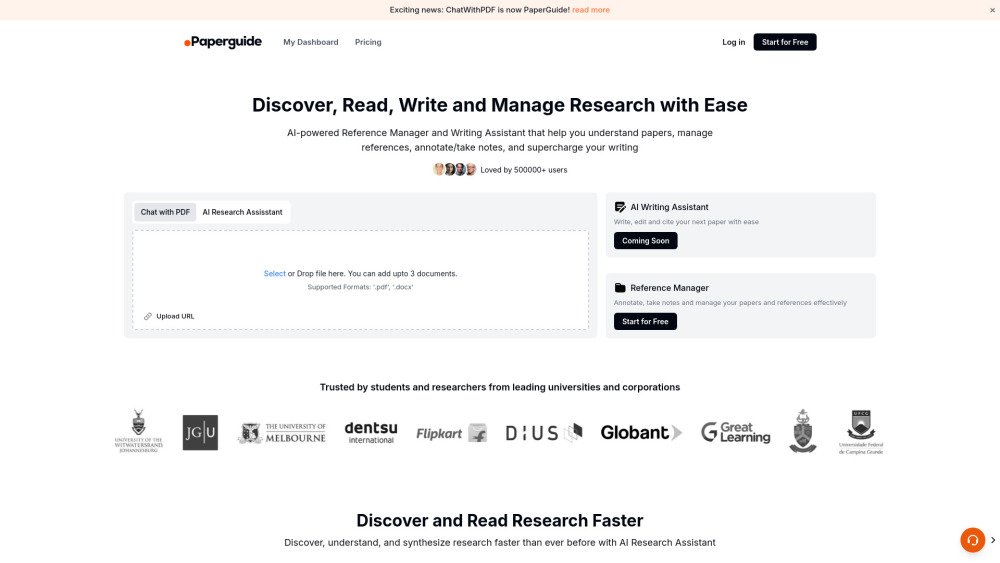
Revolutionieren Sie Ihren Forschungsprozess mit unserer KI-gestützten Plattform, die für ein nahtloses Lesen, effizientes Schreiben und eine effektive Verwaltung Ihrer Forschungsprojekte entwickelt wurde.

In der heutigen digitalen Landschaft revolutionieren Sprachklonierung und Text-zu-Sprache-Technologie die Art und Weise, wie wir Audioinhalte erstellen und konsumieren. Diese innovative Plattform ermöglicht es den Nutzern, lebensechte Voiceovers und fesselnde gesprochene Erzählungen mit bemerkenswerter Effizienz zu erzeugen. Durch den Einsatz fortschrittlicher Machine-Learning-Techniken befähigt unsere Lösung Kreative, Unternehmen und Bildungseinrichtungen dazu, qualitativ hochwertige Audioinhalte zu produzieren, die das Publikum fesseln und gleichzeitig Zeit und Ressourcen sparen. Entdecken Sie, wie diese zukunftsweisende Technologie Ihre Inhalte-Strategien optimieren und die Kommunikation verbessern kann.
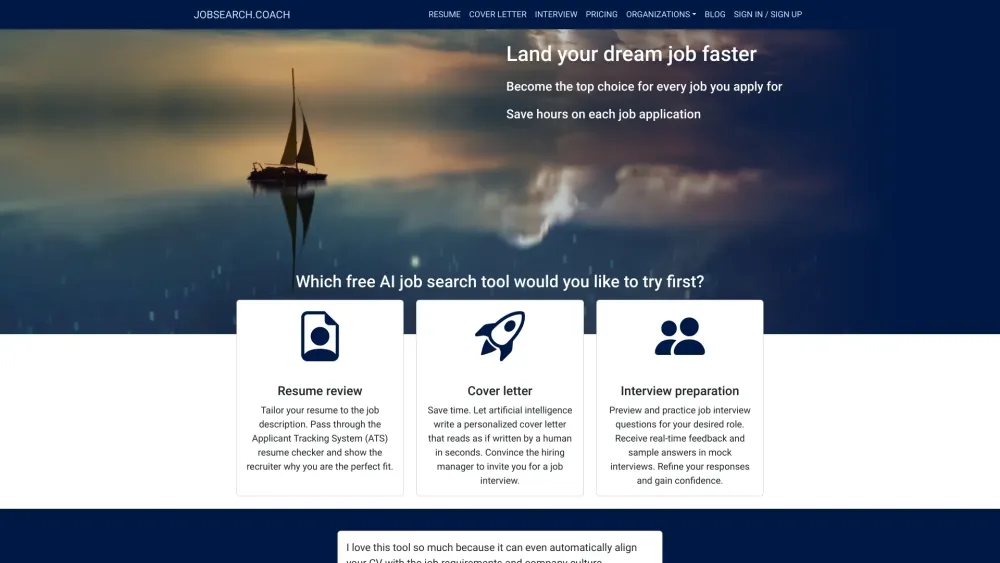
Verbessern Sie Ihren Lebenslauf und Ihr Bewerbungsschreiben für maximale Wirkung. Bereiten Sie sich auf Vorstellungsgespräche vor, indem Sie Fragen üben und sofortiges Feedback erhalten.
Find AI tools in YBX
