Google präsentiert die Gemma 2 Serie: Einführung eines 27B-Parameter-Modells, das auf nur einem TPU betrieben werden kann.
Most people like

Entdecken Sie das ultimative Webentwicklungs-Framework, das für moderne Anwendungen maßgeschneidert ist. Dieses innovative Framework ermöglicht es Entwicklern, dynamische, responsive und funktionsreiche Erlebnisse zu schaffen, die Nutzer ansprechen und die Funktionalität verbessern. Egal, ob Sie eine einfache Website oder eine komplexe Webanwendung erstellen, dieses Framework bietet die Werkzeuge, die Sie benötigen, um in der heutigen digitalen Landschaft erfolgreich zu sein.
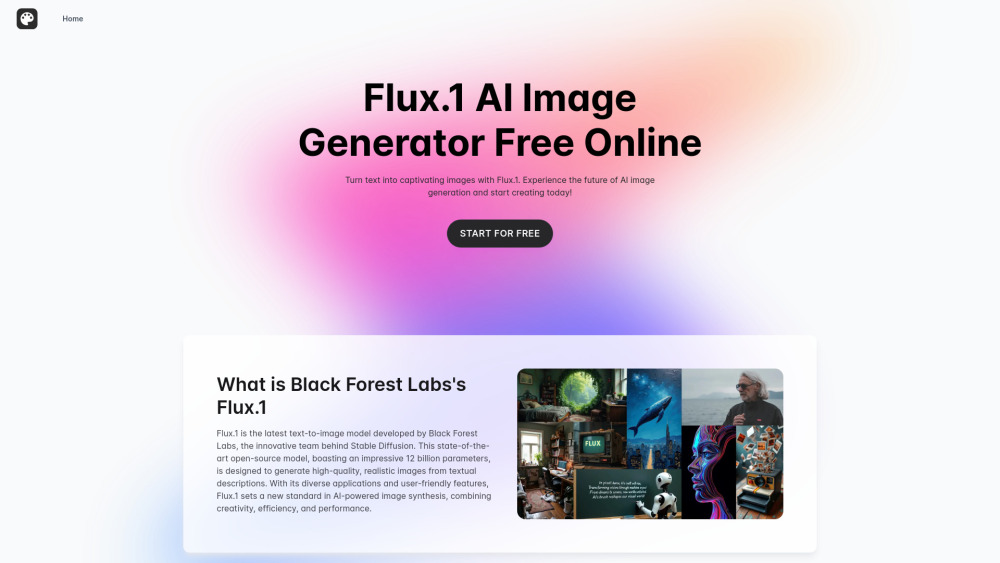
Präsentation des Flux.1 KI-Modells: Verwandeln Sie mühelos Text in beeindruckende, hochwertige Bilder – kostenlos. Entfalten Sie Ihre Kreativität und erleben Sie heute die Kraft fortschrittlicher KI-Technologie!
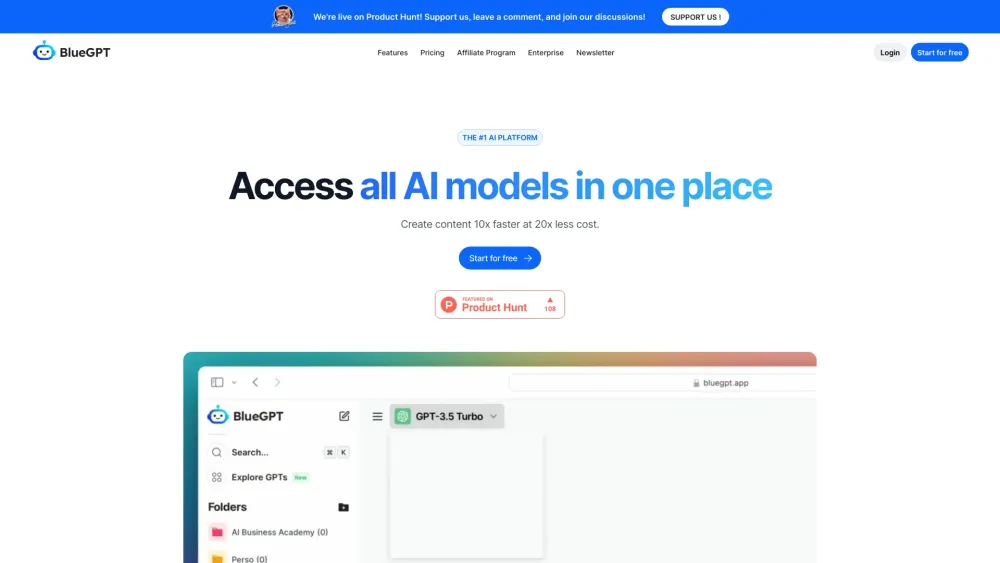
Entdecken Sie eine einzige Plattform, um nahtlos auf alle KI-Modelle zuzugreifen. Genießen Sie die Bequemlichkeit, eine Vielzahl von KI-Lösungen zu erkunden, die darauf ausgelegt sind, Ihre Projekte zu verbessern und Innovationen voranzutreiben. Ob Sie Entwickler, Forscher oder Enthusiast sind, diese Plattform bietet alles, was Sie benötigen, um die Leistung der künstlichen Intelligenz an einem leicht zugänglichen Ort zu nutzen.
Präsentation der entwicklerzentrierten KI-Suchmaschine, ein leistungsstarkes Werkzeug, das speziell für Programmierer und Entwickler konzipiert wurde. Diese innovative Plattform revolutioniert die Art und Weise, wie Sie Coding-Ressourcen, Dokumentationen und technische Lösungen finden und nutzen. Durch den Einsatz fortschrittlicher künstlicher Intelligenz liefert unsere Suchmaschine präzise Ergebnisse, die auf Ihre spezifischen Programmierbedürfnisse zugeschnitten sind, was Ihre Produktivität steigert und Ihren Entwicklungsprozess optimiert. Entdecken Sie die Zukunft des Codierens mit unserer intuitiven, KI-gestützten Suchmaschine, die darauf ausgelegt ist, Entwickler auf allen Ebenen zu unterstützen.
Find AI tools in YBX
