Erkundung von Apples neuem 'MM1' KI-Modell: Funktionen, Anwendungen und Innovationen
Most people like
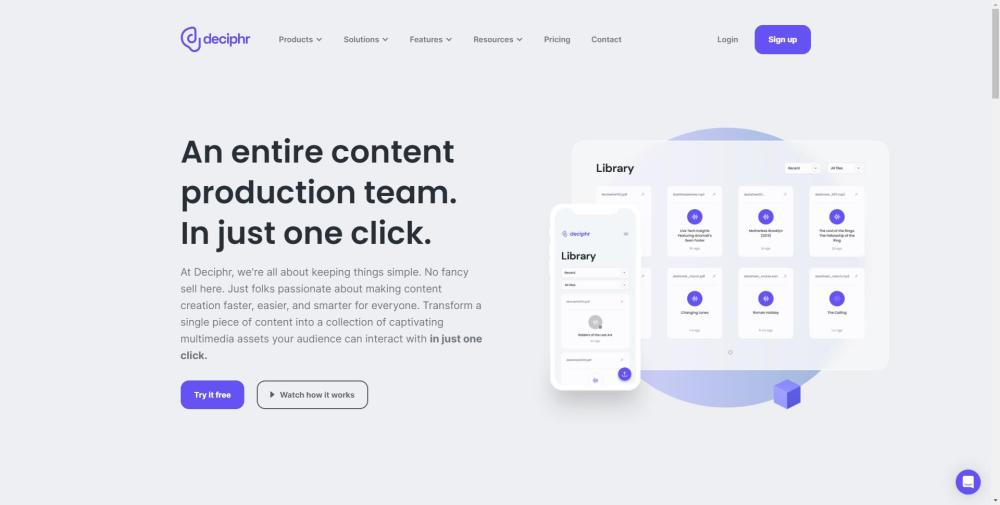
Deciphr AI revolutioniert die Inhaltserstellung mit modernen KI-Lösungen. Erleben Sie die Zukunft der Inhaltserzeugung mit leistungsstarken Werkzeugen, die Kreativität und Effizienz fördern.
Verwandeln und verbessern Sie Ihre multimedialen Inhalte mühelos mit unserer kostenlosen, KI-gestützten Plattform. Entdecken Sie, wie einfach es ist, beeindruckende Bilder und ansprechenden Audio ohne Kosten zu erstellen!
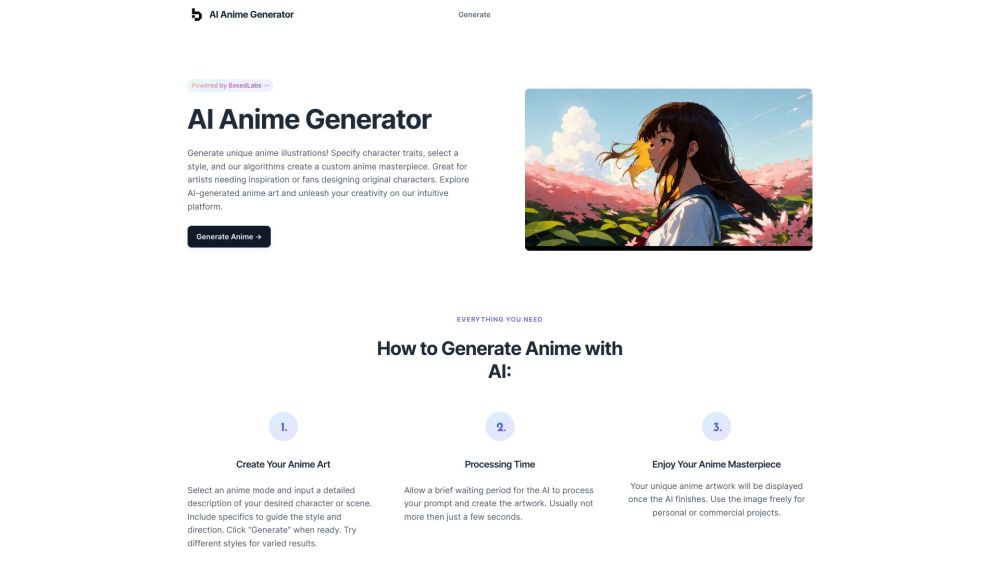
Optimieren Sie Ihre Abläufe und nutzen Sie die Kraft von KI, um Prozesse zu automatisieren und wertvolle Einblicke aus Ihren Daten zu gewinnen.
Find AI tools in YBX
Related Articles
Refresh Articles