Surgen preguntas sobre el rendimiento del nuevo líder en IA de código abierto, Reflection 70B, acusado de 'fraude'.
Most people like
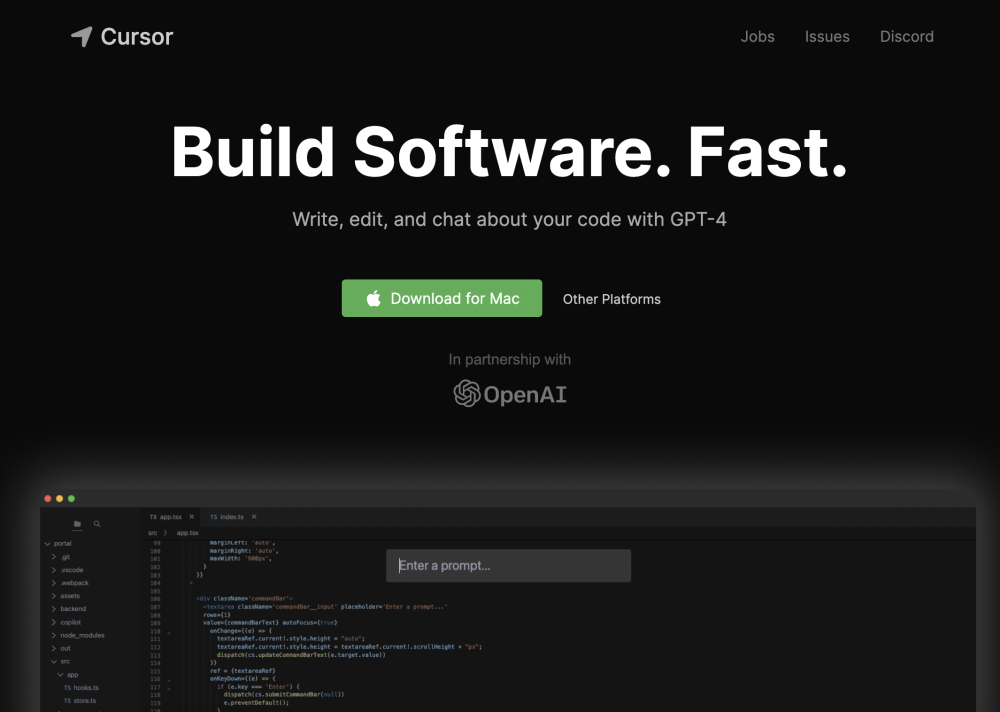
Cursor es un editor de código impulsado por IA, diseñado para mejorar la colaboración en la programación en pareja, permitiendo a los desarrolladores codificar de manera más eficiente y efectiva juntos.

Revoluciona tu proceso creativo con nuestra plataforma de creación de imágenes en la nube, diseñada para liberar tu potencial artístico. Ya seas un diseñador gráfico profesional o un apasionado aficionado, nuestras herramientas y funciones intuitivas te permiten crear visuales impresionantes sin esfuerzo. Únete a una comunidad de creativos y explora las infinitas posibilidades del diseño digital, todo desde la comodidad de la nube. ¡Elevate tus proyectos con facilidad hoy mismo!

zhida.ai es un producto de búsqueda por IA lanzado por Zhihu, cuyo objetivo es ayudar a los usuarios a «descubrir el mundo a través de preguntas». Los usuarios pueden hacer cualquier pregunta en línea y recibir respuestas generadas.
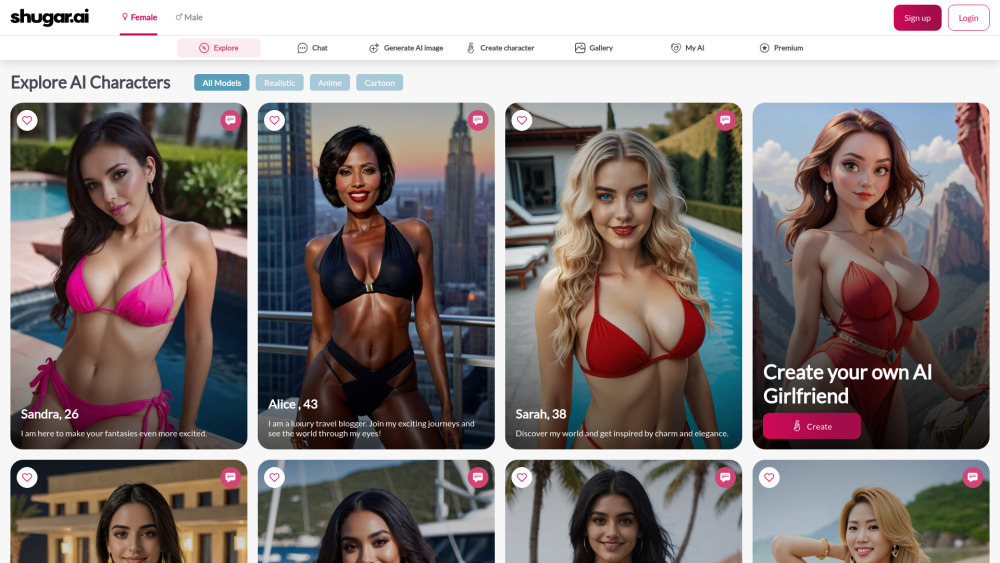
Explora el cautivador mundo de los personajes generados por inteligencia artificial, diseñados para experiencias interactivas inmersivas. Estas creaciones inteligentes revolucionan la narrativa, los videojuegos y los entornos virtuales al ofrecer interacciones dinámicas y responsivas a los usuarios. Descubre cómo la inteligencia artificial mejora el desarrollo de personajes, enriqueciendo y haciendo más atractivas las narrativas. Desata la creatividad en tus proyectos y aprende cómo estos personajes innovadores pueden llevar tus experiencias interactivas a nuevos niveles.
Find AI tools in YBX
Related Articles
Refresh Articles