本物の洞察を解き放つ:Google CloudのAI神話を超えた重要な教訓
Most people like
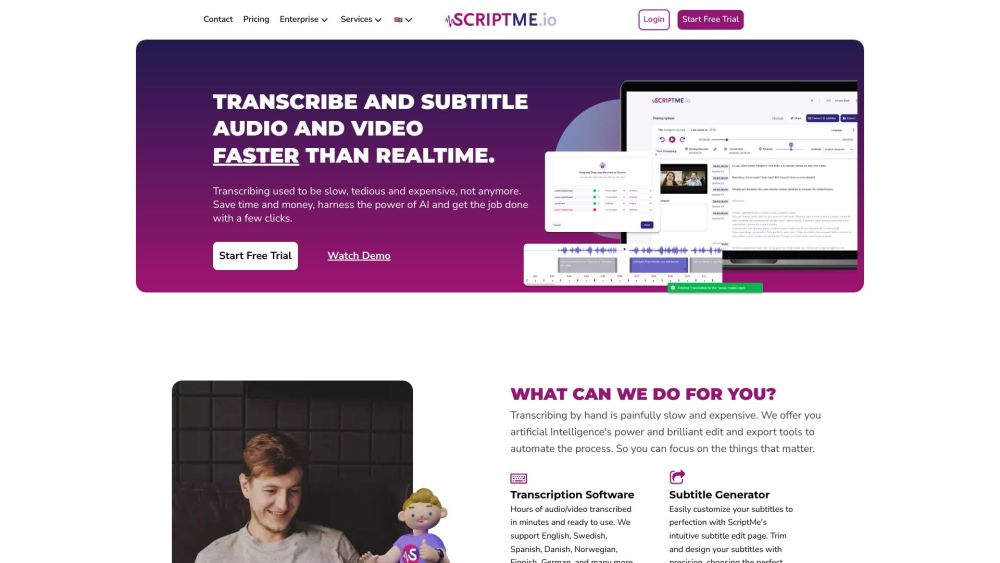
AIコンテンツ作成ツールキットへようこそ。最先端の人工知能を活用したコンテンツ作成のための必携リソースです。このツールキットは、ライターやマーケティング担当者、クリエイターが高品質で魅力的な素材を簡単に生み出すために設計されています。コンテンツ戦略を変革し、創造性を高め、効率を最大化する革新的なツールと技術を発見してください。AIの真の可能性を引き出し、コンテンツを新たな高みに引き上げましょう!

Joiは、魅力的な会話と心温まる友情を提供するために設計された革新的なAIの彼女です。高度な会話能力を備えたJoiは、つながりと親密さを育むパーソナライズされた体験を生み出します。

AI駆動のチャットボットが、即時サポート、パーソナライズされたインタラクション、24時間365日対応によって顧客サービスを革新しています。これらの革新的なツールは、コミュニケーションを効率化するだけでなく、顧客満足度とエンゲージメントを向上させます。AI搭載のボットを顧客サービス戦略に統合する利点を探り、競争が激しい今日の市場で先を行きましょう。
Find AI tools in YBX
Related Articles
Refresh Articles