AppleのオンデバイスAI技術を徹底解説:知っておくべき全情報
Most people like
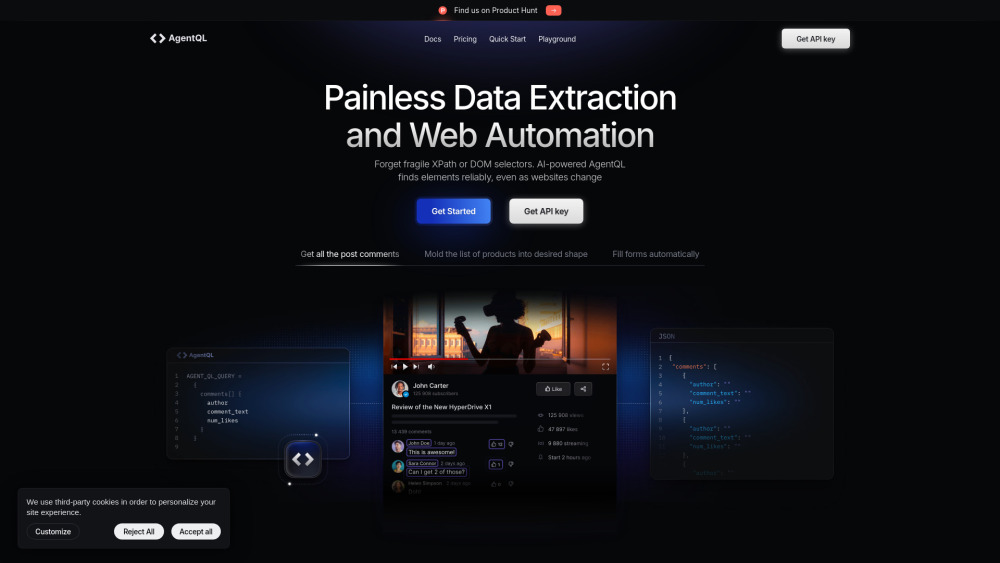
AI駆動のウェブ自動化およびデータ抽出プラットフォームを紹介します。オンラインプロセスの効率化を目的とした最先端のソリューションです。人工知能を活用して様々なウェブサイトからデータを効率的に収集し、企業が繰り返しの作業を自動化し、生産性を向上させることを可能にします。私たちのプラットフォームがどのようにあなたの業務を革新し、ウェブから貴重なインサイトを容易に引き出すことができるか探求してみてください。
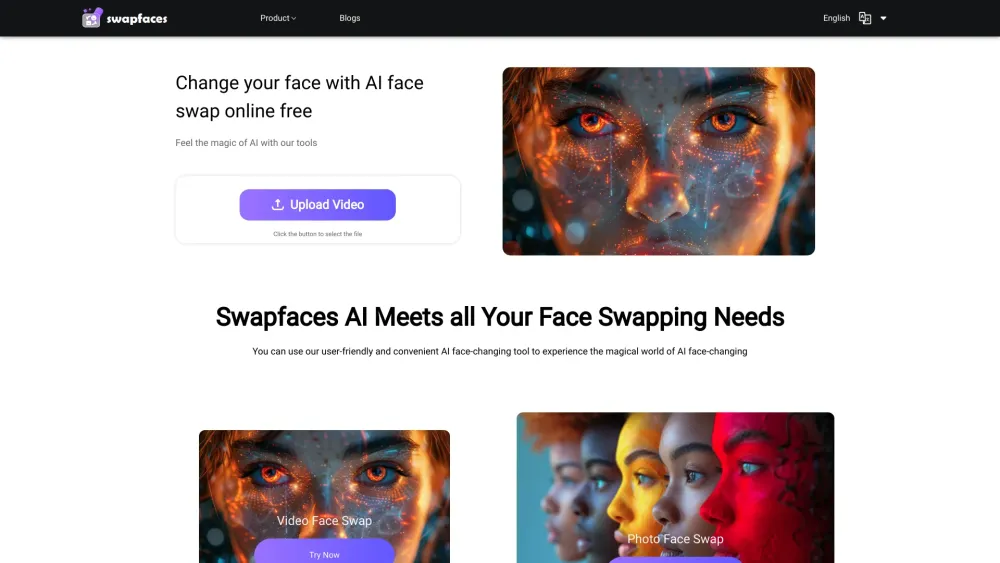
AI顔交換の魅力的な世界を発見しましょう。この最先端技術は、写真や動画で簡単に顔を交換できるようにします。高度な人工知能を活用したこの革新的なツールは、シームレスでリアルな移行を実現し、数回のクリックで視覚コンテンツを変換できます。ソーシャルメディアの投稿を引き立てたり、魅力的なミームを作成したり、クリエイティブなプロジェクトに挑戦したりする際に、AI顔交換技術は個性を持った楽しみ方を無限に広げてくれます。今日、視覚編集の未来に飛び込んでみましょう!

ファンタジー探索と没入型ロールプレイチャットのためのダイナミックなプラットフォームを発見しよう。冒険の旅に出かけ、精巧なキャラクターを作成し、スリリングなストーリーアークに参加しながら、活気あふれるコミュニティと交流しよう。熱心なロールプレイヤーでもジャンル初心者でも、私たちのプラットフォームは、あなたの想像するファンタジーの世界での体験を向上させるためのツールやリソースを提供します。今日、私たちに参加し、あなたの創造力を解き放とう!

Find AI tools in YBX
Related Articles
Refresh Articles